Everyone talks about building AI agent workflows, but most implementations hit a wall when documents don't match the schema your rules expect. You can chain tools together all day, but if your agent receives raw text dumps from poorly parsed PDFs, it starts hallucinating. That gap between demo and production comes down to whether your inputs are clean enough for the agent to trust, and it's the piece most architectures skip entirely.
TLDR:
- AI agent workflows autonomously reason, plan, and adapt to variation without fixed rules
- Enterprise adoption is accelerating fast: Gartner predicts 40% of apps will use AI agents by 2026, up from under 5% in 2025
- Sequential, parallel, and evaluator-optimizer patterns each solve different dependency structures
- Document processing agents parse, classify, extract, validate, and route files without human intervention
- Extend converts unstructured documents into LLM-ready markdown across 25 file types and 100+ languages
What Is AI Agent Workflow
An AI agent workflow is a sequence of tasks executed by one or more autonomous AI agents that can reason, plan, and act without requiring a human to direct every step. A script runs the same logic every time; an agent observes, decides, and adapts dynamically based on what it finds. That adaptability is what separates agentic workflows from traditional automation.
At the core, these workflows chain together reasoning, tool use, and decision-making. An agent might read a document, call an external API, check the result, then route to a different action depending on what it sees. Each step informs the next, so the workflow finds its own path instead of following a fixed one.
The adoption numbers reflect how fast this is moving. According to Gartner, 40% of enterprise apps will feature task-specific AI agents by 2026, up from less than 5% in 2025. That kind of jump puts agentic workflows squarely on the path from experimental to production-grade.
AI Agent Workflow vs Traditional Automation
Traditional automation like RPA excels at repetitive, structured tasks. A form with predictable fields and consistent formatting runs through an RPA bot at high volume without issues. The moment the form layout changes, a handwritten note appears, or a conditional business rule enters the picture, the bot breaks.
AI agent workflows interpret context, handle variation, and decide what to do when something unexpected appears. RPA stalls until a human rewrites the rule or updates the selector. An agent reads the new input, reasons about what changed, and adjusts its approach on its own.
| Dimension | Traditional Automation | AI Agent Workflow |
|---|---|---|
| Handles variation | No | Yes |
| Requires rule updates | Frequently | Rarely |
| Adapts to new inputs | No | Yes |
| Manages multi-step reasoning | No | Yes |
| Scales to edge cases | Limited | Strong |
The pattern in the table above is consistent: every dimension where variation or reasoning matters favors agents. In complex, exception-heavy workflows, static logic hits a ceiling fast. For high-volume, perfectly structured tasks, rule-based systems still hold up fine.
Why Enterprises Are Adopting AI Agent Workflows in 2026
According to SQ Magazine, 47% of enterprises use AI agents for workflow orchestration and automation. That figure points to a clear pattern: enterprises are deploying agents inside core production workflows, not experimenting with them in isolated demos.
That level of adoption creates competitive pressure. Teams running leaner with agent-assisted processes are pulling ahead in throughput and adaptability, while organizations still relying on rule-based automation fall further behind. What started as an interesting pilot is quickly becoming table stakes.
Core Components of AI Agent Workflows
Every AI agent workflow is built on a base AI model augmented with capabilities it wouldn't have on its own. As Anthropic's research on building effective agents notes, current models do not passively look up information. They actively generate queries, select tools, and determine what to retain in memory. While the model handles the reasoning, orchestration is where most of the system's complexity lives. Four building blocks give these systems the means to act on their decisions:
- AI model: the reasoning engine that plans, decides, and acts
- Tool integration: APIs, code execution, search, and external services the agent can call
- Memory: short-term context within a session plus longer-term retrieval from vector stores or databases
- Orchestration: the layer that sequences steps, handles branching logic, and routes between agents or tools
A single agent handling a linear task is straightforward, but multi-agent setups with specialized handoffs require clear interfaces and well-defined responsibilities. Without them, errors compound across steps.
Common AI Agent Workflow Patterns
Three patterns come up most often in production. Each one balances structure with flexibility differently, and the right choice depends on how much uncertainty the task involves.
Sequential Workflows
Steps execute in order, with each passing its output to the next. The linear structure makes them simple to reason about and easy to debug, which is why they fit best in tasks with clear dependencies where each step needs the previous result before proceeding.
Parallel Workflows
Independent subtasks run simultaneously and their results merge once all finish. Running steps in parallel cuts latency whenever they don't depend on each other, which is common in document processing pipelines where classification, extraction, and validation can all run concurrently.
Evaluator-Optimizer
One agent generates output; another scores it and sends feedback. The loop repeats until quality clears a threshold. As Claude's workflow pattern research notes, this works well when you have clear evaluation criteria but can't define the ideal output upfront.
Multi-Agent Collaboration
Specialized agents handle distinct responsibilities and hand off between each other. Keeps each agent focused on a narrow task, which reduces error surface. The tradeoff is coordination overhead, since interfaces between agents need to be clean or errors compound quickly.
Choosing the right pattern comes down to one question: how much does each step depend on the one before it? The more interdependence a workflow has, the more structure it needs.
Real-World Use Cases for AI Agent Workflows
Agentic workflows run in production across industries solving specific, high-stakes problems.
- Customer support: Agents triage incoming tickets, pull context from past interactions, draft responses, and escalate only when confidence drops below a threshold.
- Financial services: Agents parse invoices, match them against POs, flag discrepancies, and post clean entries to accounting systems without human review on every record.
- Healthcare: Agents extract clinical data from referral forms, cross-reference payer criteria, and route complete prior authorization packets for review instead of dumping raw documents on staff.
- Logistics: Agents classify bills of lading, split them from larger bundles, and parse shipper and consignee data the moment files hit the inbox, feeding downstream freight management systems automatically.
- Real estate: Agents split closing packet bundles, classify each component, validate key fields like grantors and legal descriptions, and flag anything that fails validation.
The pattern across all five is consistent: a document or input arrives, agents decide what it is, extract what matters, validate it, and route it forward. Humans step in when something genuinely needs judgment, not because the system ran out of rules to follow.
How to Build an AI Agent Workflow
The first step is defining what success looks like before touching any tooling. Vague goals produce vague agents, so precision at this stage saves debugging later.
A practical build sequence:
- Define the task and success criteria precisely: what does "done" look like, and how will you measure it?
- Map the existing workflow step by step, then identify where variation, exceptions, or judgment calls currently slow things down
- Choose an architecture that matches the task structure: sequential for linear dependencies, parallel for independent subtasks, evaluator-optimizer when quality needs iteration
- Build the smallest working version first, test against real inputs, then expand scope
- Add governance: confidence thresholds, escalation paths, and logging before going to production
Measuring AI Agent Workflow Performance
Five metrics that matter in production:
- Task completion rate: What percentage of workflows finish without human intervention or failure
- Accuracy and reliability: How often outputs meet quality thresholds across diverse inputs
- Latency and throughput: End-to-end processing time and volume capacity under load
- Autonomy score: The ratio of fully automated completions to total runs
- Cost per task: Compute and API costs relative to the value of automation
These metrics only matter when tracked against baselines, and the baselines need to be granular. A 94% task completion rate sounds strong on a dashboard, but that number drops fast when the 6% failure rate clusters around the highest-volume document type. Granular logging surfaces that kind of concentration. Aggregate dashboards often hide it.
Continuous improvement requires a feedback loop: flag low-confidence outputs, route them for review, and feed corrections back into the system. Agents that learn from mistakes hold accuracy over time. Agents that don't will drift.
Challenges and Considerations for AI Agent Workflows
Real-world implementation rarely goes as cleanly as the architecture diagram suggests, and a few recurring friction points are worth accounting for before anything reaches production:
- Integration complexity: Agents need clean interfaces to external systems. Poorly documented APIs or inconsistent data formats create failure points that are hard to debug at runtime.
- Data quality: Garbage in, garbage out. Agents are only as reliable as the inputs they receive. Upstream data inconsistencies compound across multi-step workflows.
- Governance gaps: Without confidence thresholds and escalation paths, agents fail silently. Audit logs are not optional in compliance-heavy industries.
- Agent sprawl: Teams spin up agents faster than they document or monitor them, making it hard to track what's running, what it touches, and who owns it.
- Autonomy calibration: too much autonomy and errors go uncaught; too little and you've rebuilt a manual process with extra steps.
The hardest part is not building the first agent but maintaining reliability as scope expands and edge cases accumulate.
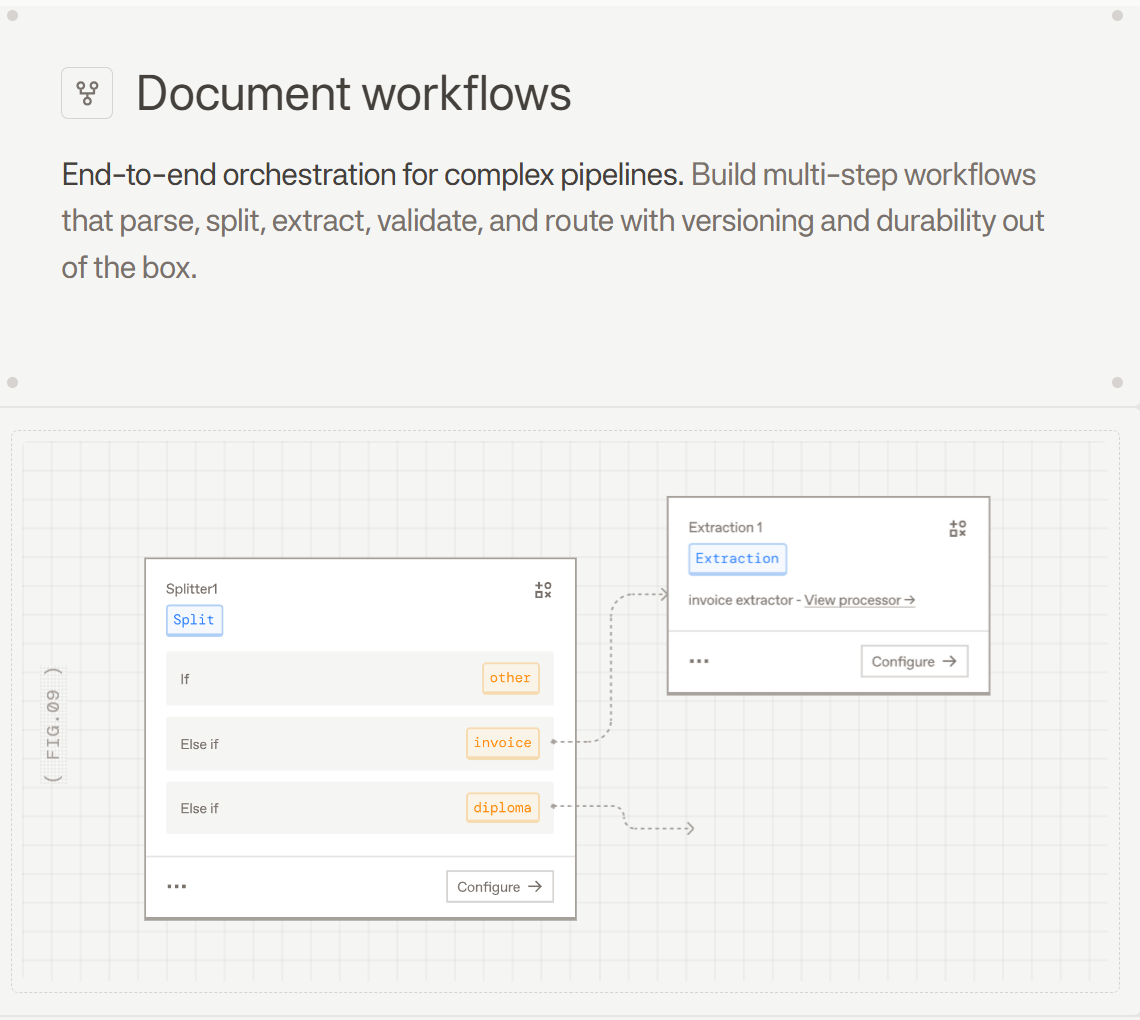
Document Processing With AI Agent Workflows
Document-centric workflows expose the hardest inputs agentic systems face. Unstructured files arrive in inconsistent formats, mixed layouts, and varying quality, and that variation is exactly why static rules break so quickly. Agents that can read, reason about, and route documents handle those inconsistencies without manual intervention at every exception.
A typical agent-managed document lifecycle starts with ingestion and parsing into structured content, followed by classification, field extraction, validation against business rules, and routing to the right downstream system. Each of those steps can branch: a low-confidence extraction triggers review, an unrecognized document type routes to a classification fallback, and a failed validation holds the record until a human clears it.
Maintaining context across multi-page files is where many implementations struggle. An agent processing a 200-page closing packet needs to understand cross-page document relationships, not treat each page as a standalone document. Without layout-aware parsing and smart chunking, the agent is left with raw text extraction fed into a prompt, which loses the structural cues it needs to reason correctly.
Human-in-the-loop review doesn't disappear in agentic document workflows; it gets more focused. Agents handle predictable volume autonomously, while humans concentrate on flagged exceptions that actually require judgment.
How Extend Powers AI Agent Workflows for Document Processing
Extend is the complete document processing toolkit comprised of the most accurate parsing, extraction, and splitting APIs to ship your hardest use cases in minutes, not months. The Parse API anchors every agentic document workflow: it converts scanned PDFs, handwritten forms, dense tables, and multi-page bundles into structured, LLM-ready markdown across 25 file types and 100+ languages. Because agents need clean inputs to reason reliably, Parse sits at the foundation of every pipeline that depends on them.
Beyond ingestion, Extend gives agents the extraction, classification, splitting, and validation steps they need to run complete workflows autonomously. The Composer AI Agent experiments with configurations to maximize extraction accuracy without manual tuning, while the Review Agent flags low-confidence outputs before they reach downstream systems. Together, they create self-optimizing pipelines where human review concentrates on genuine exceptions, not routine volume.
Final Thoughts on Deploying AI Agent Workflows
An AI agent workflow builder can run perfect logic, but it breaks the moment a document arrives in an unexpected format. Agents that adapt to variation need document inputs they can trust. Talk to Extend if you're processing complex files and need agents to work reliably at scale, because clean parsing is the difference between agents that assist and agents that autonomously close the loop.
FAQ
How do I choose between sequential and parallel workflow patterns for document processing?
Sequential workflows fit when each step depends on the previous output, like classification before extraction. When tasks are independent of each other, parallel workflows are the better choice. Running validation checks and metadata extraction simultaneously on the same parsed document is a common example.
What happens when an AI agent encounters a document type it hasn't seen before?
The agent first checks confidence scores against defined thresholds. If the score is too low, it routes the unrecognized document to a classification fallback or flags it for human review. Systems with memory and retrieval capabilities then learn from these corrections, so similar documents get handled autonomously in future runs.
Can AI agent workflows handle multi-page documents without losing context across pages?
Yes, as long as the pipeline uses layout-aware parsing and semantic chunking strategies that preserve document structure. Without those, an agent processing a 200-page closing packet will treat each page as an isolated input instead of understanding the relationships between sections.
What metrics should teams track to measure AI agent workflow reliability in production?
The five that matter most are task completion rate (workflows finishing without human intervention), accuracy against quality thresholds, latency and throughput under load, autonomy score (automated versus manual completions), and cost per task. Tracking these at a granular level reveals where failures cluster, something aggregate dashboards often hide.
When should a workflow route to human review instead of completing autonomously?
Three conditions should trigger a handoff: confidence scores dropping below defined thresholds, validation checks failing against business rules, or the agent encountering inputs outside its trained distribution. In each case, the goal is the same: concentrate human judgment on genuine exceptions instead of routine volume.
