
What is Composer
At Extend, we work with customers who process mission-critical documents. For them, accuracy isn’t optional. Any system they use has to be consistent and explainable at near-perfect accuracy.
Achieving 99%+ accuracy at scale for classification, extraction, and splitting tasks requires smart models and context engineering. The system has to understand your domain and exact use case deeply enough to resolve ambiguity across millions of messy, real-world documents.
In our experience, one of the biggest blockers for teams getting there is prompt engineering and schema optimization. We’ve seen teams spend more than half their time tweaking field descriptions, debugging, re-running evals, and chasing regressions. It’s tedious, error-prone, and doesn’t scale.
That’s why we built Composer: an AI agent that learns from your documents and optimizes your schemas automatically. Instead of tuning prompts by hand, simply point Composer at your eval set within Extend. Composer analyzes where the current schema falls short, proposes targeted improvements, and evaluates multiple experiments in parallel. It runs loop iteratively, and then surfaces diffs, accuracy gains, and the evidence behind each change. What used to take weeks of trial-and-error now happens in minutes.
During our early beta, some teams have been able to achieve 99% accuracy on challenging document tasks in under 10 minutes with Composer.
How Composer works under the hood
Composer is a background agent built to optimize schemas the same way a human would (but faster). It has access to tools for:
- Inspecting documents and outputs
- Generating schema modifications
- Searching eval results to isolate failure cases
- Testing new configurations by re-running evals
- Comparing performance across iterations
It follows a methodical process:
- Analyze — Composer inspects your current schema and compares its outputs against the ground truth in your eval set. It identifies which fields on specific documents are underperforming and why.
- Generate — For each weak spot, it creates candidate improvements. This could mean rewriting a field description to be clearer, refining an extraction rule, or proposing alternative phrasing that better captures edge cases.
- Evaluate — Each candidate schema is tested against the eval set. Composer records the accuracy gains (or regressions) at the field level, along with supporting evidence.
- Iterate — The agent repeats this process in a loop, running multiple experiments in parallel. With each iteration, it narrows in on the best-performing configuration.
Because the loop is grounded in ground truth, Composer isn’t just “guessing” — it’s measuring.
When the run completes, it surfaces:
- Diffs of every change (original vs updated schema)
- Per-field accuracy improvements in percentages
- Traces that show exactly how it reasoned through changes
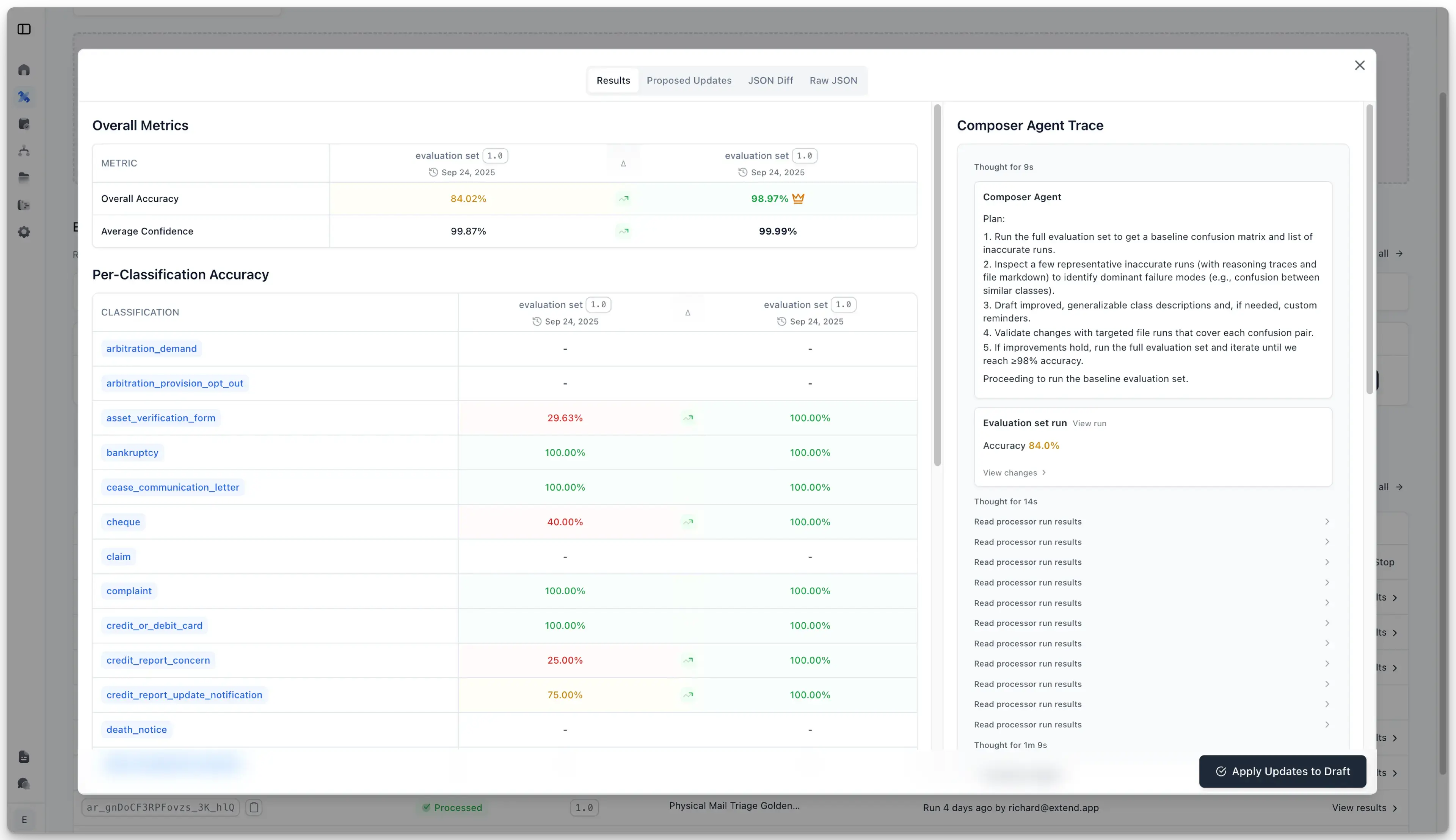
Once reviewed, you can apply Composer’s draft updates to your schema with a single click. What used to require weeks of prompt tuning and regression chasing is now a repeatable background process.
Read the docs here to learn more about how Composer works and how to get started.
Agentic Document Processing
Composer is now live for all Extend customers. Try it today on your own eval sets, and see how quickly you can achieve production-grade accuracy.
But Composer is only the beginning. We’re building a series of agents that tackle the hardest parts of working with documents, with one goal in mind: autonomous document processing.
Let our agents handle your documents, so your agents can work on what matters most.
