
Your agent is only as good as the context it gets. And for many production agents, that context still starts inside a messy PDF.
Today, we're excited to launch Parse 2.0, our SOTA document parsing API built for agents and pipelines where accuracy, cost, and latency are critical. Given any document, Parse 2.0 returns the highest quality context your agent needs to reason, act, and automate reliably.
As a companion to Parse 2.0, we're also launching RealDoc-Bench, an applied benchmark that measures parsing performance on real-world documents from logistics, healthcare, financial services, and real estate.
Unlike other benchmarks that default to simple PDFs or academic papers, RealDoc-Bench focuses on performance against the complex documents that agents actually encounter in production every day.
Evals show Extend's Parse 2.0 outperforming all other providers on RealDoc-Bench, while delivering the best combination of accuracy, speed, and cost across production document use cases.
Parse 2.0 leads on layout accuracy and document Q&A output accuracy.
Adjusted F1
Compares predicted layout regions with human annotations across 1,500 samples.
| Rank | Parser | Adjusted F1 |
|---|---|---|
| 01 | Extend Parse 2.0#1 | 0.847 |
| 02 | Reducto | 0.759 |
| 03 | AWS Textract | 0.709 |
| 04 | Azure DI | 0.687 |
| 05 | PaddleOCR-VL | 0.684 |
| 06 | DotsOCR | 0.320 |
Q&A accuracy
Tests whether parsed output returns verified values across 1,359 prompts and 581 documents.
| Rank | Parser | Accuracy |
|---|---|---|
| 01 | Extend Parse 2.0#1 | 95.7% |
| 02 | LlamaParse (Agentic) | 92.1% |
| 03 | Reducto (Agentic) | 91.1% |
| 04 | Extend Parse 1.0 | 90.4% |
| 05 | Gemini 3.5 Flash | 89.04% |
| 06 | AWS Textract | 70.5% |
Why parsing needs a better API and benchmark
At Extend, we power document pipelines and agents for hundreds of AI teams. We built RealDoc-Bench because most document benchmarks do not reflect the documents we see teams processing in production.
Too many benchmarks are dominated by clean PDFs, academic papers, or synthetic layouts. Those are useful for research, but they do not tell you whether a parser can help an agent complete tasks in the real world in industries like healthcare or logistics.
RealDoc-Bench focuses on performance against the complex documents that agents actually encounter in production every day. It includes document types like hospital intake forms, EOBs, tax forms, mortgage documents, bills of lading, and other systems-of-record documents.
The benchmark has two components:
First, layout accuracy: can the parser accurately identify meaningful regions on the page and preserve their reading order?
Second, Q&A agent performance: given the parsed output, can an LLM answer objective questions about the document correctly?
We care about both because layout alone is not enough. Other benchmarks often penalize formatting differences or evaluate isolated tasks like table transcription. Those signals are useful, but they don’t fully capture whether the parsed output works as context for an agent. Q&A agent performance measures how well an LLM can answer objective questions accurately from the parsed output, which is the true measure of parsing quality in production.
The challenging edge cases also vary by industry. Healthcare documents are filled with dense forms, checkboxes, and handwriting, while logistics teams care about performance on stamps, barcodes, and messy scans. That’s why RealDoc-Bench breaks performance down by industry, so teams can see how parsers work on documents that most closely resemble theirs.
Industry-specific slices
Select a vertical to see the same value-level metric restricted to that industry.
Financial services
380 prompts - finance documents
| Rank | Parser | Accuracy |
|---|---|---|
| 01 | Extend Parse 2.0#1 | 92.5% |
| 02 | Extend Parse 1.0 | 86.7% |
| 03 | Reducto (Agentic) | 85.7% |
| 04 | LlamaParse (Agentic) | 85.5% |
| 05 | Reducto | 83.8% |
| 06 | Gemini 3.5 Flash | 83.4% |
| 07 | LlamaParse | 83.0% |
| 08 | Azure DI | 82.6% |
| 09 | AWS Textract | 68.2% |
Read the full RealDoc-Bench blog for methodology, industry slices, side-by-side examples, and provider results: https://www.extend.ai/resources/realdocbench. We’ll be releasing a full report with more models in the benchmarks and deeper look into how we trained our models and designed the benchmark in the coming days.
What's in Parse 2.0
Parse 2.0 is trained on 1M+ real-world pages to return accurate and efficient document context for production-grade agents. Here's how the full process works:
- Parse 2.0 first runs our new layout model to understand the structure of each page. Every meaningful region is localized and classified into the following types:
| Type | Description |
|---|---|
| Text | Standalone paragraphs and body copy that sit outside tables, forms, and figures. |
| Heading | Document-level headings that introduce a major section of the page. |
| Section heading | Lower-level headings that group related content within a section. |
| Figure | Images, diagrams, logos, charts, and other non-text visual elements. |
| Table | A tabular region detected as a whole, including its headers, rows, and cells. |
| Key-value | Paired labels and values in forms and form-like layouts that aren't quite tables. Often contain handwritten text, checkbox selections, and other rich content. |
| Page number | Page number markers within the document, typically near a header or footer. |
| Barcode | Linear and 2D barcodes detected on the page. |
| Formula | Mathematical expressions and equations. |
| Header | Repeating content at the top of a page, like document IDs or branding. |
| Footer | Repeating content at the bottom of a page, like page counts or disclaimers. |
Each block is then processed further with specialized models corresponding to the type, e.g. tables route to our table model, forms to our form model, etc.
Depending on what options are set by the caller, additional models execute for further enhancement: checkbox detection, signature detection, advanced chart parsing, formatting and change/strike-through detection, and more.
Finally, our reading order model reconstructs how a human would actually read the document, and returns clean, LLM-ready markdown.
To see how that looks in practice, below is an interactive example of our layout and reading order results on a few documents from key industries.
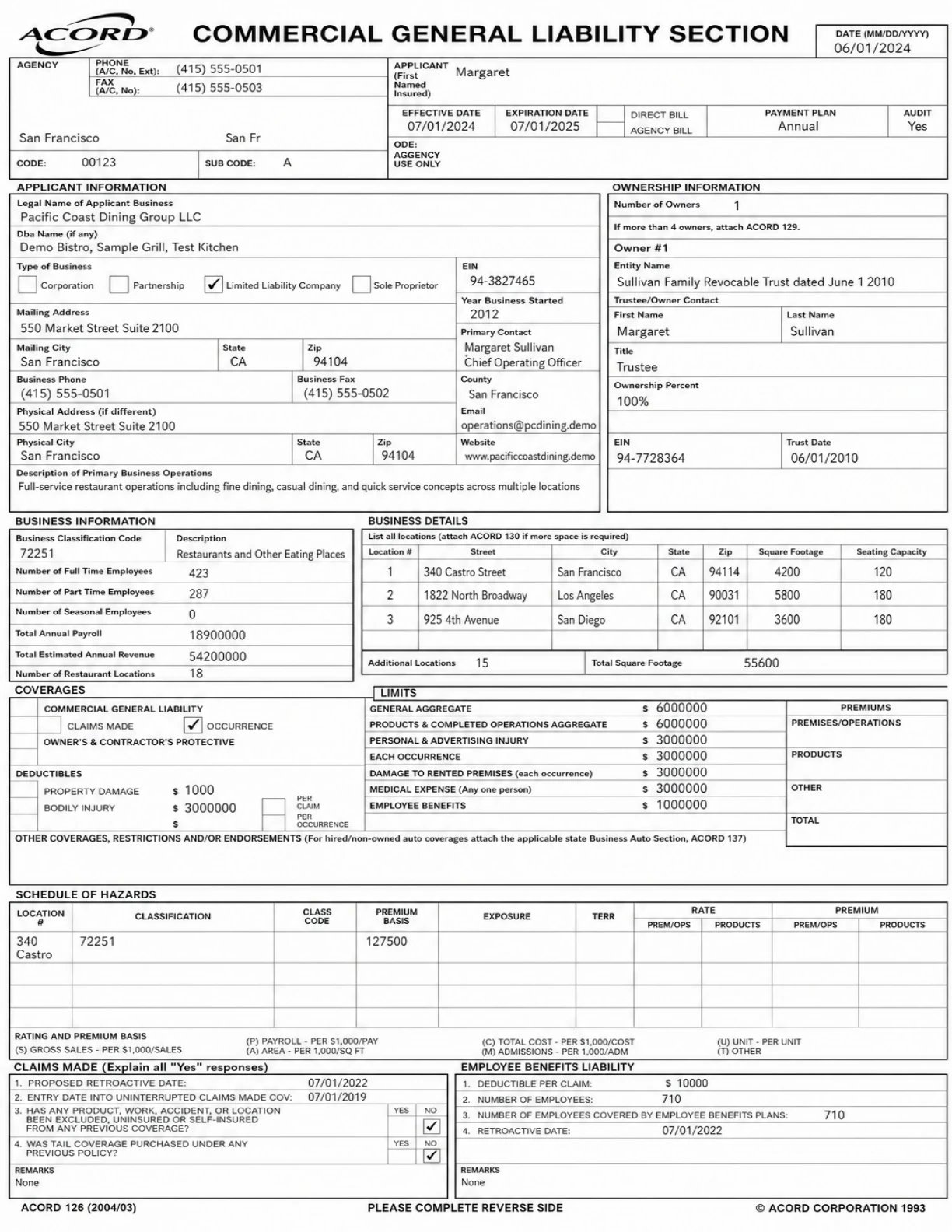
v1_acord_125_126__eastern_underwriting_acord125__p02__p03__persona01.png
* Parse 2.0 was not trained on any customer-specific data, but the design, methodology, data sourcing choices, and rigor were inspired by the thousands of hours we've spent collaborating with the hundreds of customers that use Extend in critical real world use-cases.
Available today
You can get started with Parse 2.0 today on the most cursed documents that cause issues in your pipeline: try Parse 2.0.
RealDoc-Bench resources:
- GitHub: https://github.com/extend-hq/realdoc-bench
- Hugging Face layout dataset: https://huggingface.co/datasets/Extend-AI/RealDoc-Bench-Layout/
- Hugging Face document Q&A dataset: https://huggingface.co/datasets/Extend-AI/RealDoc-Bench
We built Parse 2.0 and RealDoc-Bench from our learnings solving the toughest document challenges with hundreds of customers, processing millions of documents daily, and are the direct result of thousands of hours our team has invested in building the best document processing engine on the market.
We can't wait for you to give it a try.
FAQs
What is Parse 2.0?
Parse 2.0 is Extend's layout-first, SOTA parsing API for agents and end-to-end document automation workflows that depend on reliable inputs from complex, real-world documents. It uses our newly trained layout model, reading order models, multi-lingual OCR, and block-type specific fine-tuned VLMs to return optimal llm-ready input for any document, even the ones with dense tables, forms, checkboxes, handwriting, signatures, stamps, barcodes, formulas, and non-linear layouts.
What is RealDoc-Bench?
RealDoc-Bench is Extend's benchmark for measuring parsing performance on real-world documents from healthcare, financial services, logistics, and real estate. It evaluates both layout accuracy and downstream agent performance.
How is Parse 2.0 different from OCR, VLM, and other parsers?
Unlike single shot solutions, Parse 2.0 is a multi-model system that combines the best of OCR, vision language models and fine-tuned object detection models to create a parsing engine optimized for complex documents seen across logistics, financial services, healthcare, real estate and other critical industries. Foundational to Parse 2.0 is our new SOTA layout and reading order models, and frontier VLMs fine-tuned for fast reliable handling of document specific tasks like chart understanding, table processing, and dense form parsing.
Legacy OCR extracts text and coordinates but fails on docs with complex layouts, and the outputs aren't optimized for agent ingestion.
One-shot VLM parsing can output text, but full page generation is non-deterministic, expensive, slower at production throughput, and difficult to control.
Other parsers optimize for clean PDFs but struggle to maintain reading order, complex tables, and multi-column forms, and are prone to hallucination, especially dense form regions.
Parse 2.0 is built for production document workflows where downstream systems depend on accurate outputs.
