When you're extracting data from documents at scale, one question haunts every production system: how confident should I be in this result?
The industry-standard in LLM-based extraction has relied on two signals: OCR confidence and logprobs. The problem is that these confidence scores don't tell us what we actually need to know.
OCR confidence tells you how visually certain the system is that the text it extracted matches what's actually in the document. This is useful if the scan is blurry or the handwriting is ambiguous. But OCR confidence doesn't tell you anything about whether that correctly-read text actually answers the question you asked.
Logprobs confidence comes from the LLM itself, representing the model's token-level probability distribution during generation. In theory, this should capture semantic uncertainty. In practice, logprobs are more of a signal about how well the output aligns with the model's pre-training distribution than about extraction correctness. A model can be highly "confident" (high logprobs) while producing an answer that's wrong for reasons it can't introspect on, like misunderstanding which of two similar values in a document was actually requested.
Both metrics share a fundamental limitation: they're measuring the wrong thing. What we actually need to know is not "did we read this correctly?" or "does this token sequence seem likely?" but rather "does this extracted value correctly answer the schema's intent given what's in this document?"
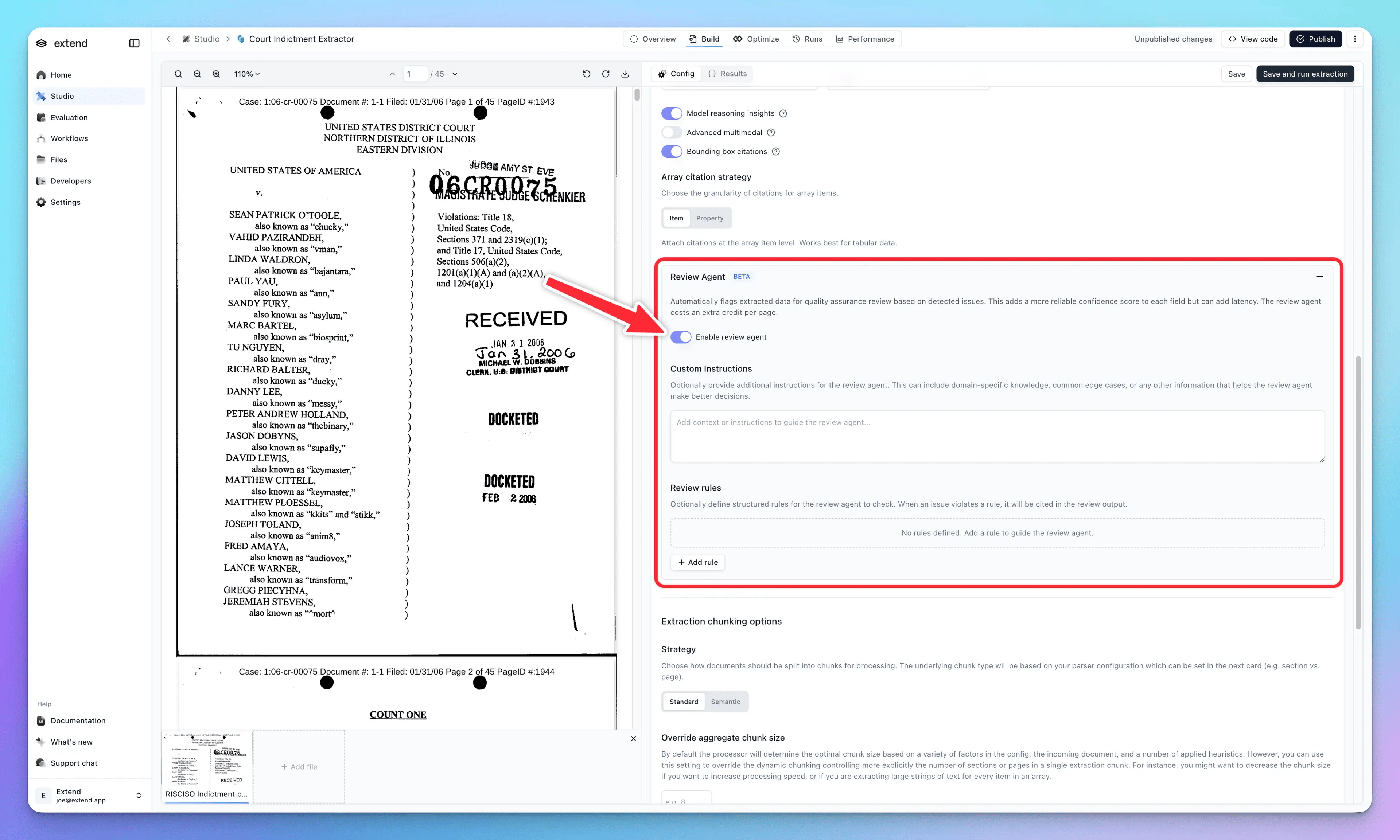
That’s why we shipped Review Agent—a new way to measure extraction confidence. Review Agent is an agentic system that takes a second pass over every extraction with a critical lens, asking: where could there be problems here? Is this value actually grounded in the document? Does this answer match what the schema is asking for? Are there multiple valid interpretations?
The output is a confidence score from 1-5, but more importantly, it surfaces why that score exists. You get cited examples of issues it found—ambiguous field values, potential mismatches between the extraction and document content, cases where the schema definition left room for interpretation.
True Confidence Requires Self-Analysis
The realization that led to Review Agent was that producing a meaningful confidence score requires the model to reason about its own extraction—to take a critical second look and ask probing questions.
Where could there be ambiguity in how the schema was interpreted? Are there multiple candidate values in the document that could plausibly match this field? Does the extracted value actually satisfy the field description, or is it a near-miss? These are the questions a human reviewer would ask, and answering them requires analytical reasoning, not statistical measurement.
This is why Review Agent is an agent rather than a simple post-processing step. It analyzes the extraction output in context, identifies potential issues, and synthesizes those findings into a confidence score. The score emerges from structured reasoning about uncertainty.
How Review Agent Works
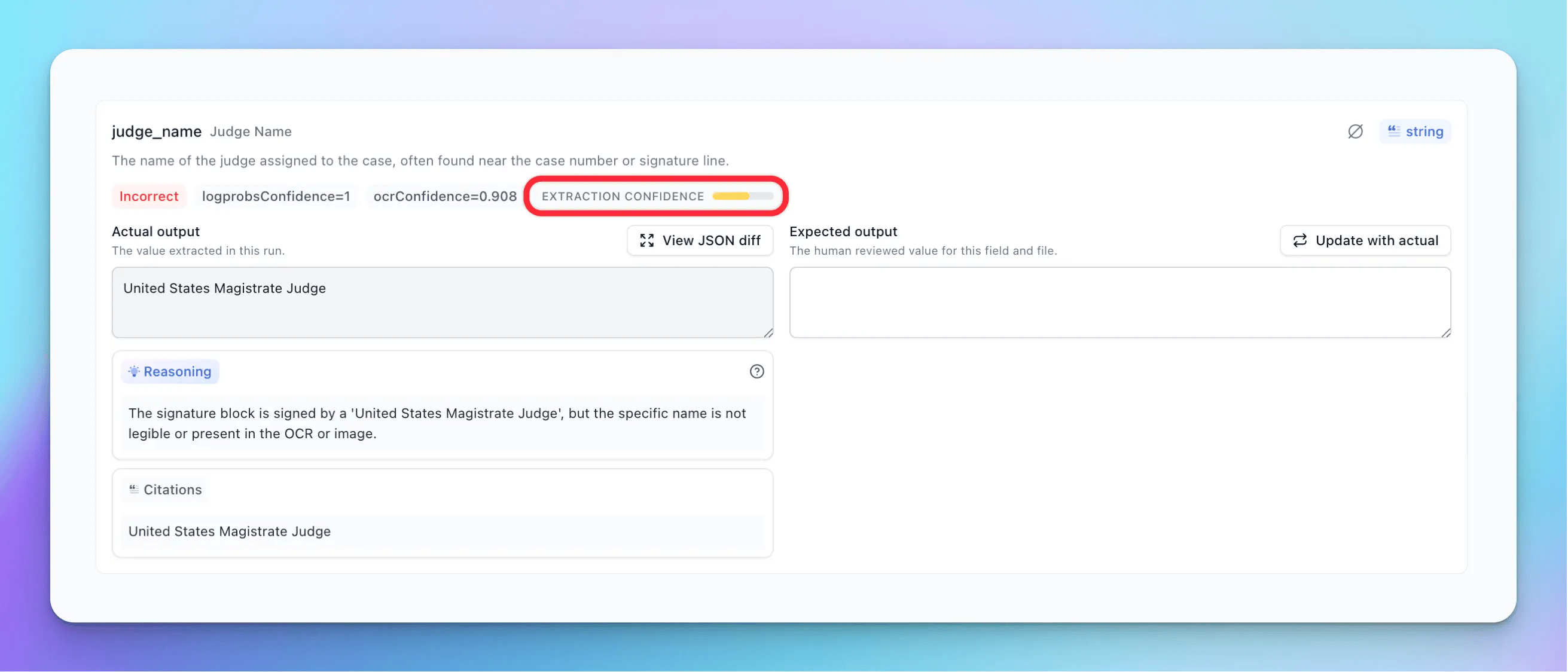
When Review Agent runs, it examines each extracted field against the source document and schema definition. It's looking for several categories of issues, such as:
- Extraction errors: Cases where the value is demonstrably wrong given the document content.
- Ambiguity: Situations where multiple values in the document could plausibly match the field.
- Schema interpretation issues: Cases where the field description is vague enough that reasonable interpretations could yield different results. If the schema asks for "amount" without specifying whether that means subtotal, total, or balance due, and the document contains all three, that's a schema problem that manifests as extraction uncertainty.
- Rule violations: User-defined rules that encode domain-specific requirements. If you've specified that all names must be real identifiable names (not titles like "Magistrate Judge"), Review Agent checks for violations.
For each issue found, Review Agent assesses severity and factors it into a final 1-5 score:
- 5: High confidence, no issues detected
- 4: Good confidence, minor observations or precautionary notes
- ≤ 3: Usually warrants review. The agent found issues worth correcting
The specific threshold depends on your accuracy requirements.
The Hybrid Approach: Efficiency Meets Insight
One of the key design constraints was efficiency. A fully agentic approach—spinning up a multi-turn reasoning chain for every field—would add substantial latency and cost. That's fine for complex research tasks, but document extraction often needs to process hundreds of pages quickly.
Review Agent takes a hybrid approach. It runs as a single efficient pass after extraction, structured to maximize insight while minimizing overhead. We wanted something you could flip on and forget—running on every document by default without having to pick and choose which extractions need more scrutiny.
The result is a system that's comprehensive enough to give you real insight into why a score is what it is, but efficient enough to be practical at scale.
Steering with Rules and Instructions

Review Agent accepts two forms of guidance: unstructured and structured rules.
Unstructured rules let you provide free text direction: "Be very critical of fields that don't have extracted data" or "Pay special attention to date format consistency." These shape the overall behavior of the review process.
Structured rules encode specific requirements that, if violated, should flag an issue. You can mark rules as "critical"—if a critical rule is broken, the score for that element drops to 1, regardless of other factors. This is useful for hard business requirements, like if you want a name field to always include full names. Providing structured rules helps the review agent look for and hone in on these problems, and marking them as critical ensures that problematic extractions won’t slip past without review.
The distinction matters because Review Agent is context-aware in a way that simple rule engines aren't. Providing context about why certain business logic exists can help the agent enforce said logic. By providing multiple formats for user instruction, we can make sure that the review agent gets both.
The Unexpected Benefit: Schema Feedback
One of the most valuable things we've seen from Review Agent in practice wasn't something we explicitly designed for: it teaches users about their own schemas.
When you see Review Agent repeatedly flagging ambiguity on a particular field—"the document contains both X and Y, and the schema doesn't specify which one is wanted"—that's direct feedback that your schema definition needs work. It's the same insight you might eventually get from reviewing extraction errors manually, but surfaced proactively and systematically.
This creates a virtuous cycle. You tighten the schema description to resolve the ambiguity, and not only does Review Agent stop flagging it, but the extraction itself becomes more consistent. The agent becomes a tool for schema refinement, not just extraction QA.
We saw something similar with Composer, our extraction agent—users ended up learning why their schemas were problematic through the system's behavior. Review Agent extends this to the confidence and review layer.
Practical Integration
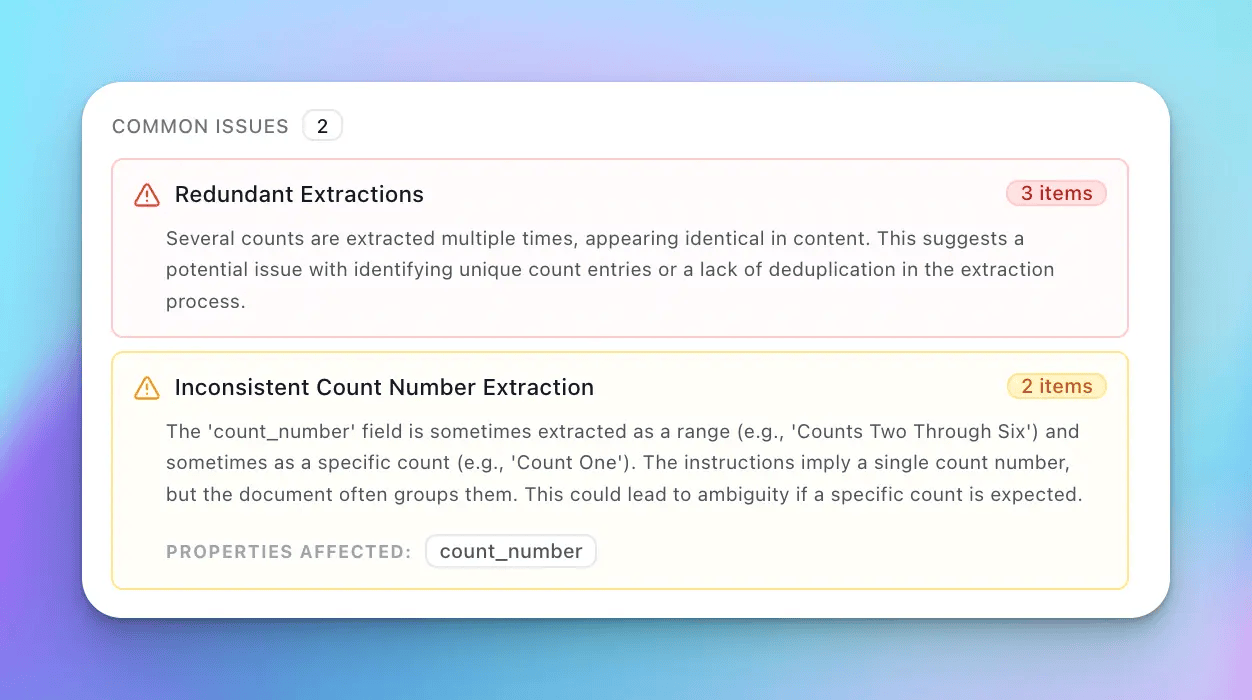
Review Agent integrates at both the UI and API level. In the UI, you'll see extraction confidence gauges that expand on hover to show the specific issues found and their severity. For arrays, there's a heatmap view that helps you quickly identify which items need attention.
Via API, you enable Review Agent through advancedOptions.reviewAgent.enabled and get back reviewAgentScore and insights in the metadata for each field. The insights array contains structured issue objects with severity and content, making it straightforward to build programmatic review workflows.
For workflow automation, you can route based on score thresholds: send anything scoring 3 or below to human review, let 4s and 5s proceed automatically. The extraction step exposes summary variables like minReviewAgentScore and numFieldsFlaggedForReview for coarse-grained routing decisions.
What's Next
Review Agent is a foundation for where we're headed: increasingly autonomous document processing. The same machinery that produces confidence scores—structured reasoning about extraction quality—is a building block for systems that can self-correct, iterate on schemas, and handle edge cases without human intervention.
We're continuing to refine the agent's ability to identify subtle issues and provide actionable feedback. The goal isn't just "flag this for review" but "here's exactly what's uncertain and why, so you can fix it at the source."
For now, Review Agent is available in Advanced Settings for all extractors. Read the docs for review agent to learn more
Flip it on, run your evaluation set through, and see what it surfaces. You might be surprised what you learn about your schemas.
