When your payer rejects a CMS 1500 because the diagnosis pointer in field 24E doesn't match field 21, you're looking at another 30 to 60 days before reimbursement. These rejections happen constantly with manual processing where staff miss field relationships or misread handwritten codes. Automated CMS 1500 form processing catches those mismatches before submission by validating every field against payer rules. Here's how healthcare providers are using OCR and vision AI to process forms faster and cut denial rates in half.
TLDR:
- CMS 1500 rejections from field mismatches delay reimbursement by 30 to 60 days, with denial rates hitting 11.81% in 2024.
- Automated processing using OCR and VLMs validates field relationships before submission, catching diagnosis pointer errors, missing authorization numbers, and demographic mismatches that cause rejections.
- Vision AI handles handwritten diagnosis codes and mixed-format entries with 98%+ accuracy, processing claims in seconds instead of the 5 to 10 minutes required for manual entry.
- Healthcare providers cut denial rates by 50% and reduce per-claim processing costs by catching errors pre-submission instead of managing rework after payer rejection.
- Implementation with pre-trained models achieves production-level accuracy in days, allowing your billing teams to scale claim intake without adding headcount.
Understanding CMS 1500 Form Structure and Components
The CMS-1500 form is the standard paper claim used by non-institutional healthcare providers to bill Medicare, Medicaid, and most commercial insurers. This two-page form contains 33 numbered fields that capture patient demographics, insurance details, diagnosis codes, and services provided.
The top section (fields 1-13) collects patient and insurance information, including policy numbers and group identifiers. The middle section (fields 14-23) records service details, such as dates of service, place of service, CPT/HCPCS codes, diagnosis pointers, and prior authorization numbers. The bottom section (fields 24-33) captures billing information, including the services provided, charges, provider identifiers, and additional administrative codes needed for processing the claim.
While 80 to 90% of claims now flow through the electronic 837P format, the CMS 1500 structure remains foundational for healthcare operations. Paper claims still apply for corrected claims, appeals, and situations where electronic submission isn't available.
Common Errors That Cause CMS 1500 Processing Failures
Processing failures on CMS 1500 forms typically stem from a handful of recurring issues that payers flag immediately. The most common culprits include patient demographic mismatches, missing prior authorization numbers, and diagnosis codes that don't align with the procedures billed.
Patient information errors rank among the top rejection triggers. Typos in names, transposed digits in member IDs, or outdated insurance policy numbers cause payers to reject claims outright. Date of birth mismatches between the form and payer records similarly halt processing before any medical review occurs.
Missing or incorrect authorization numbers in field 23 create another frequent bottleneck. Many procedures require pre-authorization, and without the correct reference number, payers deny the claim regardless of medical necessity. Field 24E diagnosis pointers must correctly reference the diagnosis codes listed in field 21, or the claim fails basic validation checks.
Incomplete provider information in fields 32 and 33 also triggers rejections. Missing facility names, incorrect NPI numbers, or unsigned forms get kicked back before adjudication begins. 26% of providers report 10% of denials stem from inaccurate or incomplete data collected at patient intake.

Manual vs. Automated CMS 1500 Form Processing
Manual processing of CMS 1500 forms follows a predictable workflow: staff receive paper forms, type field values into billing software, verify insurance eligibility, and submit claims through clearinghouses. This approach works for small practices with limited claim volumes but introduces human error at every step. A single transposed digit or misread handwritten code can delay reimbursement by weeks.
Automated processing removes the manual typing layer. OCR and VLM capabilities extract field values directly from scanned forms, converting images into structured data that flows into billing systems. Automation handles handwriting variations, detects checkbox states, and validates field relationships in seconds instead of minutes. The shift to automation reduces per-claim processing time while improving data accuracy, allowing organizations to scale claim intake without proportionally increasing headcount.
| Feature | Manual Processing | Automated Processing |
|---|---|---|
| Processing Time per Claim | 5-10 minutes | Seconds |
| Error Rate | 10-15% | Less than 2% |
| Handwriting Recognition | Limited by staff interpretation | VLM-powered recognition with 98%+ accuracy |
| Pre-Submission Validation | Manual review required | Automatic field relationship checks |
| Scalability | Requires proportional headcount increase | Handles volume spikes without additional staff |
| Cost per Claim | Higher labor costs plus rework expenses | Lower processing costs with reduced denials |
| Denial Rate Impact | Higher due to data entry errors | 50% reduction in denial rates |
The Financial Impact of CMS 1500 Processing Errors
Processing errors on CMS 1500 forms create direct revenue cycle damage that extends far beyond the initial claim rejection. Initial denial rates climbed to 11.81% in 2024, meaning one in every eight claims requires rework before payment. Each denied claim triggers administrative costs as staff identify errors, correct data, resubmit claims, and track appeals through resolution.
Cash flow impact compounds quickly. Denied claims delay reimbursement by 30 to 60 days on average, pushing revenue recognition into future quarters. For practices operating on thin margins, these delays strain working capital and force reliance on credit lines to cover operating expenses.
Rework costs accumulate as staff investigate rejections, contact payers for clarification, and manually correct forms that should have been accurate on first submission. Higher processing accuracy through intelligent document processing reduces denial rates, accelerates payment cycles, and frees staff to focus on patient care instead of claim appeals.
OCR Technology for CMS 1500 Data Extraction
OCR extracts data from CMS 1500 forms by analyzing scanned images or digital PDFs and converting printed text into machine-readable values. The tech identifies character shapes, maps them to text, and outputs structured field values that billing systems can ingest directly. For forms with clear printing and proper alignment, basic OCR delivers reliable results across most fields.
The challenge surfaces when forms arrive with poor scan quality, misaligned pages, or handwritten entries mixed with typed text. CMS 1500 forms pack 33 fields into a dense grid, creating situations where characters bleed across field boundaries or shadows obscure digit clarity. Handwritten diagnosis codes and provider signatures add complexity that traditional OCR struggles to parse accurately.
Machine learning models trained on millions of healthcare documents handle these variations by recognizing handwriting patterns, correcting for skewed scans, and interpreting character sequences within the context of expected field types using document extraction AI. Advanced OCR reaches accuracy rates exceeding 98% on structured forms.
Vision AI and Complex Form Element Detection
Vision AI goes beyond text recognition to interpret visual elements that define CMS 1500 forms. VLMs detect checkbox states in fields 1-3 (insurance type selection), locate handwritten signatures in fields 12 and 31, and parse dense table layouts in section 24 where service lines span multiple columns.
Character-per-box fields like NPIs and policy numbers require vision AI document processing tools with spatial understanding to map individual characters into their designated boxes, especially when handwriting crosses boundaries. Physician notes and diagnosis codes often appear in cursive or shorthand that standard OCR misinterprets entirely.
VLMs handle these scenarios by analyzing spatial relationships, understanding form structure, and recognizing element types before attempting extraction. The models route checkboxes to detection pipelines, signatures to verification workflows, and handwritten text to specialized recognition models trained on medical documentation patterns.
Best Practices for CMS 1500 Processing Workflows
Workflow optimization starts with standardizing intake procedures before documents reach processing systems. Consistent naming conventions, scan quality requirements, and field validation rules reduce variability that leads to downstream errors.
Pre-submission validation catches issues before claims leave the organization. Automated checks using IDP tools verify patient demographics against payer databases, confirm diagnosis pointers match service codes, and flag missing authorization numbers. Building validation into the workflow prevents rejections that delay payment cycles.
Staff training needs regular refreshment on payer-specific requirements and common error patterns. Teams should understand which fields trigger automatic rejections versus manual review, allowing them to focus on accuracy where it matters most.
Quality control checkpoints at key workflow stages catch errors early. Reviewing samples of processed claims daily identifies systemic issues like recurring field mapping problems or scan quality degradation before they affect large claim batches.
AI-Powered Document Processing for Healthcare Claims
AI processing applies LLM and VLM capabilities to understand field relationships and validate data coherence across CMS 1500 forms. These models verify that diagnosis pointers in field 24E correctly reference diagnosis codes in field 21, confirm service dates fall within coverage periods, and flag inconsistencies between procedure codes and documented medical necessity.
The systems handle large patient charts spanning 1,000+ pages without context cutoffs, maintaining accuracy across multi-document claim packages. They adapt to state-specific form variations, payer-specific field requirements, and format changes without requiring manual template updates.
AI validation catches compliance issues before submission by cross-referencing extracted values against coding guidelines and payer rules in healthcare document processing. The models learn from correction patterns, improving accuracy on forms with unusual layouts or non-standard entry methods that deviate from typical CMS 1500 formatting. Human-in-the-loop document processing feeds corrections back into processing pipelines, creating continuous improvement cycles that refine extraction logic for edge cases.
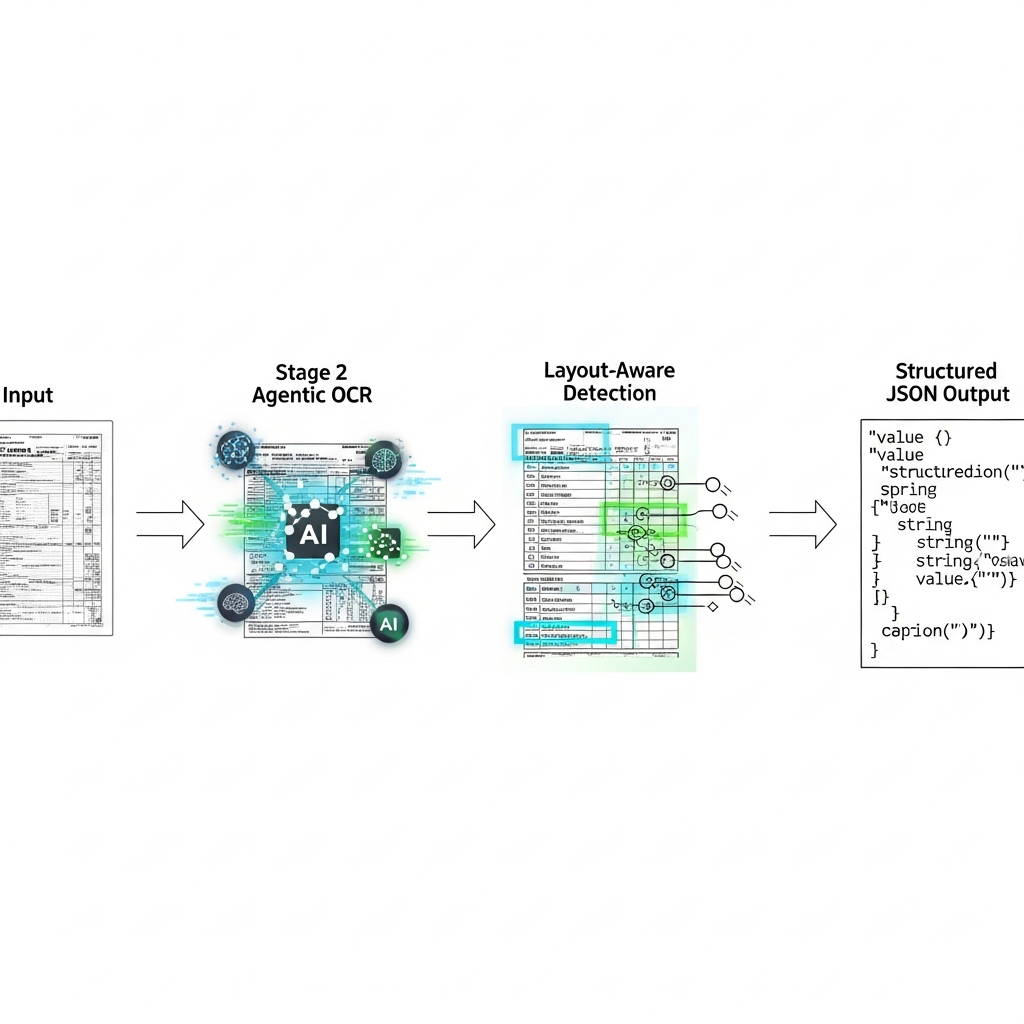
How Extend Processes CMS 1500 Forms
Extend's document processing infrastructure applies agentic OCR and custom VLMs to parse CMS 1500 forms with field-level precision. The system detects checkboxes in insurance type fields, extracts handwritten diagnosis codes, and parses character-per-box NPIs regardless of penmanship variations or form misalignment.
Layout-aware models identify every form element before extraction begins, routing handwritten sections through specialized recognition pipelines while processing typed fields through optimized OCR paths. The vision AI handles section 24's dense service line tables, maintaining accuracy across all columns even when entries span multiple rows or pages.
The extraction API outputs structured data with precise bounding boxes for every field value, creating audit trails that link extracted data back to source locations on the original form.

Final Thoughts on Improving CMS 1500 Data Extraction
Automating CMS 1500 processing changes how fast your claims move through the revenue cycle. Your denial rates drop when VLMs catch field errors before submission instead of after payer rejection. The shift from manual typing to automated extraction scales claim intake without adding headcount to your billing department.
If processing accuracy matters to your bottom line, set up a call to walk through how Extend handles your specific form challenges.
FAQs
What is a CMS 1500 form and why is it important?
The CMS 1500 form is the standard paper claim used by non-institutional healthcare providers to bill Medicare, Medicaid, and commercial insurers. It contains 33 numbered fields capturing patient demographics, insurance details, diagnosis codes, and services provided. While most claims now flow electronically through the 837P format, the CMS 1500 structure remains foundational for corrected claims, appeals, and situations where electronic submission isn't available.
How does automated processing reduce CMS 1500 denial rates?
Automated processing reduces denial rates by validating field relationships before submission. The system catches errors like diagnosis pointer mismatches between field 24E and field 21, missing authorization numbers, and patient demographic inconsistencies that typically cause rejections. Pre-submission validation prevents claims from being denied for data quality issues, cutting denial rates by up to 50% compared to manual processing.
What are the most common errors on CMS 1500 forms?
The most common errors include patient demographic mismatches (typos in names, transposed member IDs, incorrect dates of birth), missing or incorrect prior authorization numbers in field 23, diagnosis pointers in field 24E that don't correctly reference diagnosis codes in field 21, and incomplete provider information in fields 32 and 33. These errors trigger immediate rejections before payers even review the medical necessity of claims.
How long does it take to implement automated CMS 1500 processing?
Implementation timelines vary based on claim volume and system complexity. Organizations using pre-trained processing models can achieve production-level accuracy in days, not months. The setup involves integrating extraction APIs with billing systems, configuring validation rules for payer-specific requirements, and setting up review workflows for flagged claims. Most providers see measurable improvements in processing speed and accuracy within the first week of deployment.
What is the financial impact of CMS 1500 processing errors?
Processing errors create direct revenue cycle damage through denied claims, delayed reimbursement, and rework costs. With initial denial rates reaching 11.81% in 2024, one in eight claims requires correction before payment. Each denied claim delays reimbursement by 30 to 60 days on average, straining cash flow and forcing reliance on credit lines. Rework costs accumulate as staff investigate rejections and manually correct forms that should have been accurate on first submission.
How does OCR technology handle handwritten CMS 1500 forms?
Advanced OCR systems use vision AI and machine learning models trained on millions of healthcare documents to recognize handwriting patterns, correct for skewed scans, and interpret character sequences within expected field types. VLMs handle handwritten diagnosis codes, physician signatures, and cursive notes that traditional OCR misinterprets. Modern systems reach accuracy rates exceeding 98% on structured forms, even with mixed handwritten and typed content.
Can Extend process state-specific CMS 1500 variations and high-volume claims?
Extend handles state-specific form variations, payer-specific field requirements, and format changes without requiring manual template updates. The system processes large patient charts spanning 1,000+ pages without context cutoffs and scales to handle volume spikes without additional staff. Layout-aware models identify every form element before extraction, routing handwritten sections through specialized recognition pipelines while processing typed fields through optimized OCR paths.
