Fixed-size chunking treats your documents like flat text files, splitting every N tokens regardless of semantic boundaries. This scatters contextually related information across chunks and degrades RAG retrieval accuracy. Semantic chunking uses sentence embeddings to detect topic transitions while preserving logical document structure. Teams see improved retrieval precision by tuning similarity thresholds (0.5-0.8), adding overlap windows, and validating performance against baseline approaches.
TLDR:
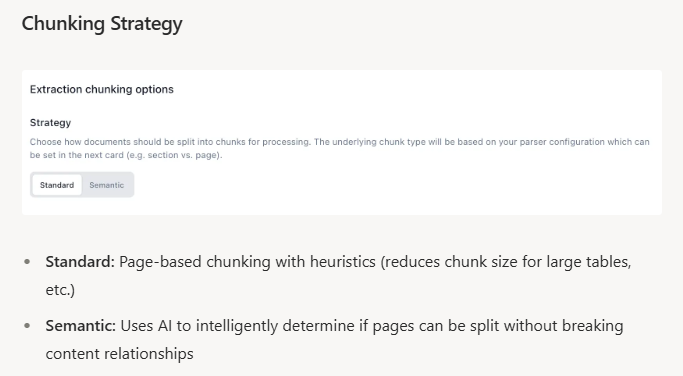
- Semantic chunking analyzes meaning to find natural boundaries, producing variable-length chunks that preserve context
- Use domain-specific models and tune thresholds (0.7-0.8 for technical docs, 0.5-0.6 for narrative content)
- Optimal chunk sizes vary: 64-128 tokens for fact-based queries, 512-1024 for complex reasoning tasks
- LangChain and LlamaIndex offer production-ready libraries with configurable embedding models
- Extend combines semantic chunking with layout-aware parsing to maintain context across tables and forms
What Is Semantic Chunking
Semantic chunking splits documents based on meaning, not fixed character counts or token limits. The process embeds sentences using models such as sentence-transformers and measures cosine similarity between adjacent embeddings. When similarity falls below a defined threshold, the system inserts a boundary, signaling a topic shift.
This produces variable-length chunks that align with the document’s logical structure during ingestion. A single chunk might cover a brief discussion of pricing, while another spans an extended explanation of a technical workflow, yielding contextually coherent segments that better preserve intent and improve RAG retrieval quality.
How Semantic Chunking Works
The process begins with sentence segmentation using a splitter such as NLTK or spaCy, treating each sentence as a discrete unit of comparison. These sentences are then passed through an embedding model during document ingestion to produce dense vector representations that capture semantic meaning.
The system computes cosine similarity between consecutive sentence embeddings, generating a similarity profile across the document. High similarity scores indicate related topics, while sharp declines signal potential topic transitions.
Chunk boundaries are determined using one of two primary strategies. Threshold-based methods apply a fixed similarity cutoff, creating a new chunk whenever adjacent sentences fall below that value. Distance-based methods instead analyze the rate of change in similarity, splitting when the distance between embeddings exceeds a percentile derived from the document’s overall similarity distribution.
Sentences between boundaries are merged into coherent segments, with optional overlap windows that pull in neighboring sentences to preserve context at chunk edges.
Semantic Chunking vs Fixed-Size Chunking
Fixed-size chunking splits documents every N tokens or characters regardless of content. The approach is computationally cheap and predictable, making it easy to implement for high-volume pipelines where speed matters more than precision. Semantic chunking analyzes meaning to find natural boundaries, producing variable-length chunks that preserve context.
Fixed-size chunking delivers faster processing and consistent chunk sizes. Semantic chunking requires embedding computation and similarity calculations but returns contextually intact segments that improve retrieval accuracy through document extraction AI when answer quality matters more than latency.
| Method | Processing Speed | Chunk Size | Context Preservation | Best Use Case |
|---|---|---|---|---|
| Fixed-Size Chunking | Fast - minimal computation required | Predictable - consistent N tokens or characters | Low - splits occur regardless of semantic boundaries | High-volume pipelines where speed matters more than precision |
| Semantic Chunking | Slower - requires embedding computation and similarity calculations | Variable - adapts to natural topic boundaries | High - preserves logical document structure | RAG applications where answer quality and context accuracy are critical |
5 Best Practices for Implementing Semantic Chunking
1. Choose Domain-Appropriate Embedding Models
Choose domain-appropriate embedding models that match document complexity. Sentence-transformers like all-MiniLM-L6-v2 handle general text quickly, while all-mpnet-base-v2 works better for technical documents with specialized terminology. Legal or medical content benefits from domain-specific embeddings trained on industry corpora in intelligent document processing.
2. Tune Similarity Thresholds
Tune similarity thresholds based on document structure. Technical documentation with frequent topic shifts needs higher thresholds (0.7-0.8) for granular chunks, while narrative content requires lower thresholds (0.5-0.6) to preserve context. Test thresholds on representative samples to balance coherence with retrieval precision.
3. Add Overlap Windows
Add 1-3 sentence overlap windows at chunk boundaries to prevent information loss when answers span multiple segments, improving answer completeness without major storage increases.
4. Tag Chunks with Metadata
Tag chunks with metadata like section headers, page numbers, and document type to create retrieval signals beyond semantic similarity.
5. Monitor Performance Metrics
Track chunk size distribution, boundary accuracy, and RAG metrics like answer precision to identify performance degradation with new document types.
Advanced Semantic Chunking Methods
Several variations extend basic semantic chunking with different similarity calculation strategies. Statistical chunking analyzes the entire document's similarity distribution before splitting, using percentile-based thresholds that adapt to each document's content density.
Consecutive chunking compares only adjacent sentences, creating boundaries when immediate similarity drops. Cumulative chunking adds each new sentence to a running chunk embedding, comparing the growing segment against the next sentence to detect when adding more content dilutes coherence.
Max-min semantic chunking tracks both local similarity drops and overall coherence within potential chunks. The method creates boundaries when the minimum similarity between any two sentences falls below a threshold, preventing topically mixed segments even if average similarity stays high.
These methods involve different computational tradeoffs for RAG systems. Consecutive chunking processes linearly with minimal memory overhead. Cumulative methods require recalculating embeddings as chunks grow. Statistical and max-min approaches need multiple similarity computations per boundary decision.
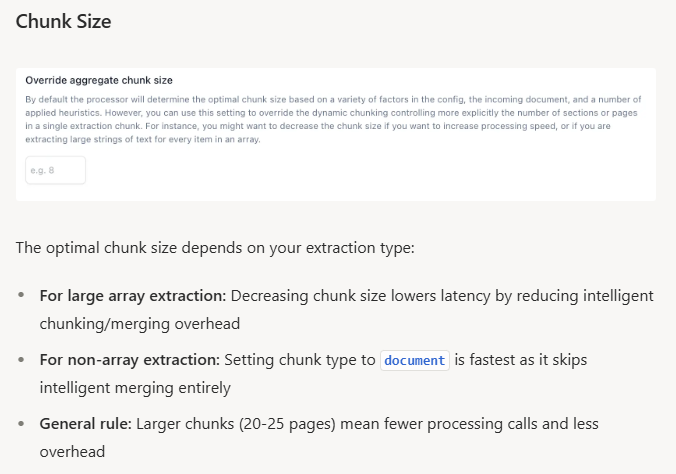
Optimizing Chunk Size for RAG Performance
Chunk size selection depends on document structure and query complexity. Page-level chunking achieved 0.648 average accuracy with the lowest variance across datasets, providing reliable baseline performance.
For fact-based queries, 64-128 token chunks optimize retrieval precision by reducing noise. Financial records and technical specifications benefit from smaller chunks that isolate discrete facts.
Questions requiring broader understanding need 512-1024 token chunks that preserve context. Legal reasoning and medical case analysis require larger segments to capture relationships between concepts.
Test chunk sizes against representative query patterns from actual usage to identify the optimal range for each document type.
Evaluating Semantic Chunking Effectiveness
Track retrieval accuracy by comparing semantic chunking against fixed-size baselines using identical query sets. Measure whether top results contain correct answers (precision), how quickly you find the first correct result (ranking), and whether chunks include all needed context (completeness).
Test with 50-100 actual user questions, not synthetic examples. Sample 20-30 chunk boundaries per document type to verify splits occur at topic transitions, not mid-concept. Deploy A/B tests routing half of production queries to each method to validate real-world improvements.
Semantic Chunking in Production Document Processing with Extend
Extend's document processing pipeline combines semantic chunking with layout-aware OCR and VLMs to handle complex documents. The system detects document structure during parsing, then applies semantic boundaries that respect both meaning and layout, preventing chunks from splitting mid-table or mid-form.
Extend's agentic extraction pipeline processes thousands of line items across multi-page tables with nested data table extraction while maintaining relational context. The Composer AI agent automatically experiments with chunk configurations and schema variants through self-improving document processing systems, converging to production-ready accuracy in minutes.
Extend chains classification, splitting, extraction, and evaluation into end-to-end pipelines. The Review Agent flags low-confidence extractions for human verification, creating feedback loops that improve chunking and extraction accuracy over time.
Final Thoughts on Semantic Chunking Methods
Semantic chunking produces variable-length segments that follow topic flow instead of breaking mid-paragraph at fixed intervals. The approach trades faster processing for better context preservation, which matters when your RAG system needs to return complete answers. Tune your similarity thresholds based on document density and track boundary quality through manual review of actual splits. If your documents mix structured data with narrative text, reach out to see how Extend applies semantic boundaries while respecting layout structure.
FAQ
How do I choose the right similarity threshold for semantic chunking?
Start with 0.5-0.6 for narrative documents and 0.7-0.8 for technical content with frequent topic shifts. Test thresholds on 50-100 representative samples from your actual document corpus, then track retrieval precision to validate the setting works for real queries.
What embedding model should I use for semantic chunking?
Use all-MiniLM-L6-v2 for general text processing where speed matters, or all-mpnet-base-v2 for technical documents requiring higher accuracy. Legal and medical documents need domain-specific embeddings trained on industry corpora to handle specialized terminology correctly.
When should I use semantic chunking instead of fixed-size chunking?
Use semantic chunking when retrieval accuracy matters more than processing speed and when your documents have clear topic boundaries that fixed-size methods might split incorrectly. Switch to fixed-size chunking for high-volume pipelines where consistent latency and predictable chunk sizes outweigh quality gains.
How large should my chunks be for RAG applications?
Use 64-128 tokens for fact-based queries on financial records or specifications, and 512-1024 tokens for complex questions requiring broader context like legal reasoning or medical analysis. Test both ranges against your actual query patterns to find the optimal size for each document type.
Can semantic chunking handle multi-page tables and forms?
Semantic chunking alone often splits tables mid-row or separates form fields from their values. Hybrid approaches that combine semantic boundaries with layout detection work better—Extend's pipeline uses layout-aware OCR to detect structural elements, then applies semantic chunking that respects both meaning and document structure.
