Most document extraction systems output confidence scores on every field they pull. The problem shows up when you try to use those scores for routing decisions. Document processing confidence scores need calibration to match their stated confidence with actual accuracy in production. An uncalibrated model might claim 95% confidence while only being correct 72% of the time, which makes threshold-based automation impossible. Calibration fixes the gap between what scores promise and what they deliver.
TLDR:
- Confidence scores quantify AI certainty in document extraction, letting teams auto-process high-scoring outputs while routing uncertain predictions to human review.
- Calibrated scores make certain that 90% confidence actually maps to 90% real-world accuracy, preventing blind trust in miscalibrated model outputs.
- Setting thresholds balances precision vs recall: higher thresholds reduce errors but increase manual review, lower thresholds improve coverage but allow more mistakes through.
- Feedback loops track correction data to reveal when models are over or underconfident, allowing teams to adjust thresholds as performance changes over time.
- Extend combines calibrated confidence scoring with a multi-pass review agent that flags potential errors before production, achieving 99%+ accuracy.
What Are Confidence Scores in Document Processing
Confidence scores are numerical values that quantify how certain an AI model is about its predictions during document extraction. These scores typically range from 0 to 1, where values closer to 1 indicate higher certainty and values closer to 0 suggest the model is less confident in its output.
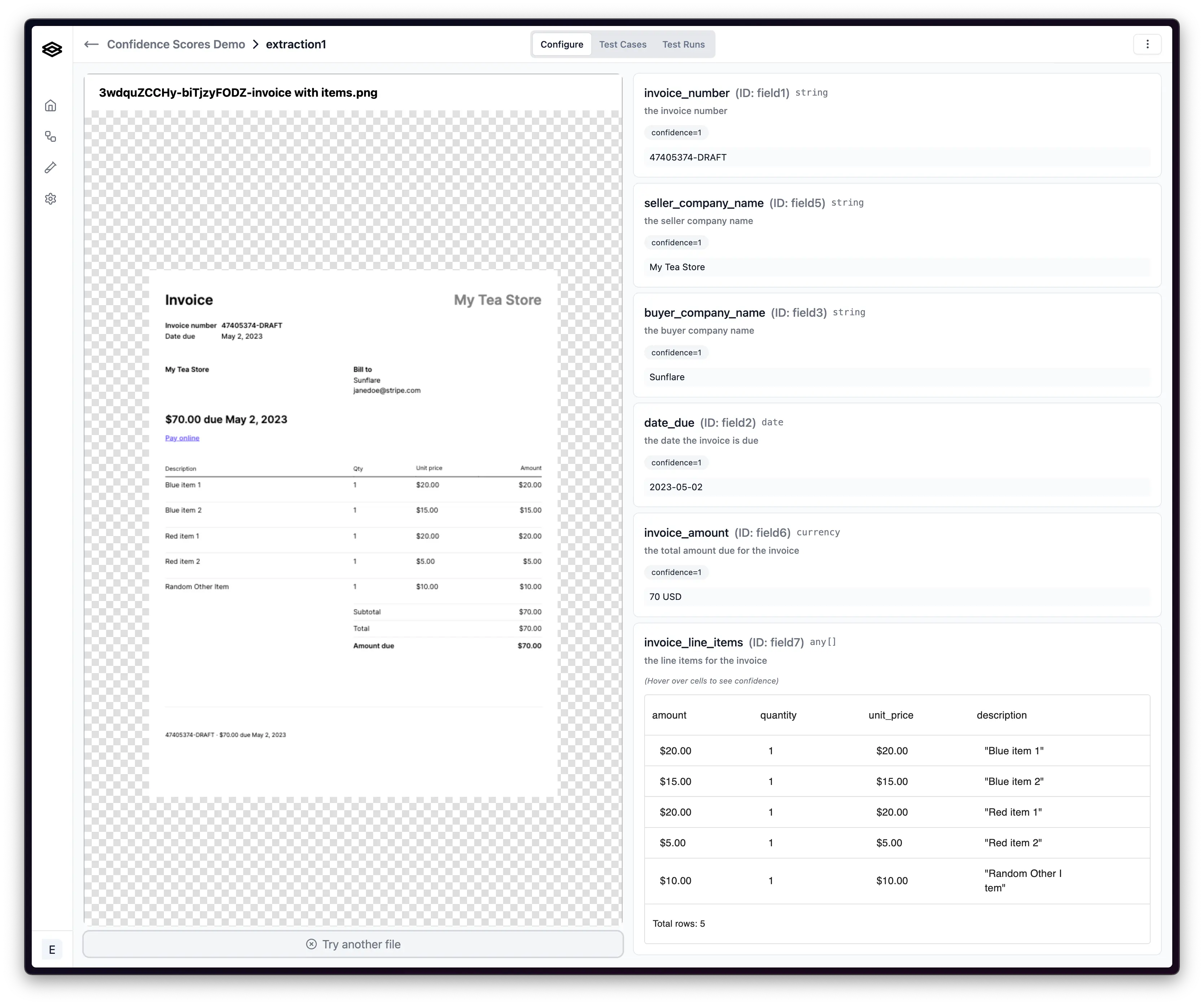
When an LLM or vision model extracts data from a document, such as pulling an invoice number or total amount, it generates a confidence score alongside each extracted field. This score reflects the model's internal assessment of whether it correctly interpreted the document content.
Confidence scores act as automated quality gates in document processing workflows. Teams can route high-confidence extractions straight through to downstream systems while flagging low-confidence predictions for human review. This creates a triage system where only uncertain outputs require manual attention.
Why Confidence Scores Matter for Document Automation
Document automation has scaled across enterprise organizations, with 63% of Fortune 250 companies now running IDP solutions. Financial services leads adoption at 71%, processing loans, claims, and compliance documents at volume. Confidence scores make this scale viable.
Without confidence scores, automation forces an all-or-nothing choice. Organizations either trust every extraction blindly or review every document manually. Both fail at scale. Blind automation pushes errors into downstream systems. Universal review negates automation benefits.
Confidence scores solve this. Teams can auto-process 80-90% of documents meeting confidence thresholds while routing edge cases to human reviewers. This ratio lets document processing scale with business growth instead of headcount.
Calibration: The Foundation of Reliable Confidence Scores
Calibration determines whether confidence scores actually mean what they claim. A calibrated confidence score of 90% should correspond to 90% real-world accuracy across documents. When a model outputs 95% confidence, that extraction should be correct 95 times out of 100.
Most AI models output raw probability estimates that don't match real-world performance. A model might assign 95% confidence to predictions that are only correct 70% of the time. This miscalibration breaks trust in automation systems. Teams either ignore scores entirely or waste time reviewing documents that didn't need human eyes.
Proper calibration aligns model confidence with actual accuracy through statistical adjustments. This process analyzes how often predictions at each confidence level prove correct on validation data, then applies corrections to future scores.
Calibrated scores let teams set thresholds with predictable outcomes. Route everything above 92% confidence for auto-processing. Send 70-92% scores to review queues where human validation makes sense.
Common Confidence Score Metrics in Document Processing
Expected Calibration Error (ECE) measures the gap between predicted confidence and actual accuracy across confidence bins. Teams group predictions by confidence level, then calculate the absolute difference between average confidence and accuracy in each bin. Lower ECE values indicate better calibration.
Precision-recall curves plot the trade-off between correct positive predictions and coverage at different confidence thresholds. Higher thresholds increase precision but reduce recall, catching fewer total documents. Teams analyze these curves to find the threshold that balances accuracy requirements against manual review capacity.
Reliability diagrams visualize calibration by plotting predicted confidence against observed accuracy. Perfect calibration follows a diagonal line where 80% confidence matches 80% accuracy. Deviations show where models are overconfident or underconfident at specific score ranges.
Setting Effective Confidence Thresholds for Your Workflows
Confidence thresholds act as decision gates in document workflows. The score set determines which documents auto-process and which require human review. There's no universal standard since different use cases carry different risk profiles.
Most teams start with three confidence bands. High confidence extractions (90-100%) move straight through to downstream systems. Medium confidence outputs (70-89%) route to review queues. Low confidence predictions (<70%) trigger manual re-entry or escalation.
| Confidence Band | Score Range | Routing Action | Typical Use Case |
|---|---|---|---|
| High Confidence | 90-100% | Auto-process to downstream systems | Standard invoices, clear documents with consistent formatting |
| Medium Confidence | 70-89% | Route to human review queue | Poor quality scans, unusual layouts, ambiguous handwriting |
| Low Confidence | <70% | Manual re-entry or escalation | Heavily damaged documents, completely unknown formats |
These ranges serve as starting points, not rules. Invoice processing for accounts payable might require 95% thresholds because payment errors create vendor disputes. Contract metadata extraction could accept 85% thresholds since legal teams review contracts anyway.
Calculate thresholds by mapping confidence levels to error tolerance. If the business can absorb 2% errors in a workflow, find the confidence score where 98% of documents process correctly.
Thresholds also depend on review capacity. Teams with small operations staff set higher thresholds to keep review queues manageable.
How Confidence Scores Support Human-in-the-Loop Workflows
Human-in-the-loop workflows use confidence scores to route documents through different processing paths based on AI certainty. This creates a triage system where high-confidence extractions bypass review entirely while uncertain predictions land in validation queues.
The routing logic works through conditional branches. Documents scoring above threshold values go directly into downstream databases or systems. Scores below threshold trigger review tasks assigned to operations teams. This separates the 85-90% of documents AI handles confidently from cases that need human judgment.
Review queues sort by confidence level and business impact. Critical fields like payment amounts might trigger review at 92% confidence while reference numbers only flag below 75%. Teams can also weight specific field types differently based on downstream consequences of errors.
This tiered approach focuses reviewer time on documents where AI struggles: poor scans, unusual formats, or ambiguous handwriting. The confidence score acts as the decision point that makes selective review possible without sacrificing accuracy.
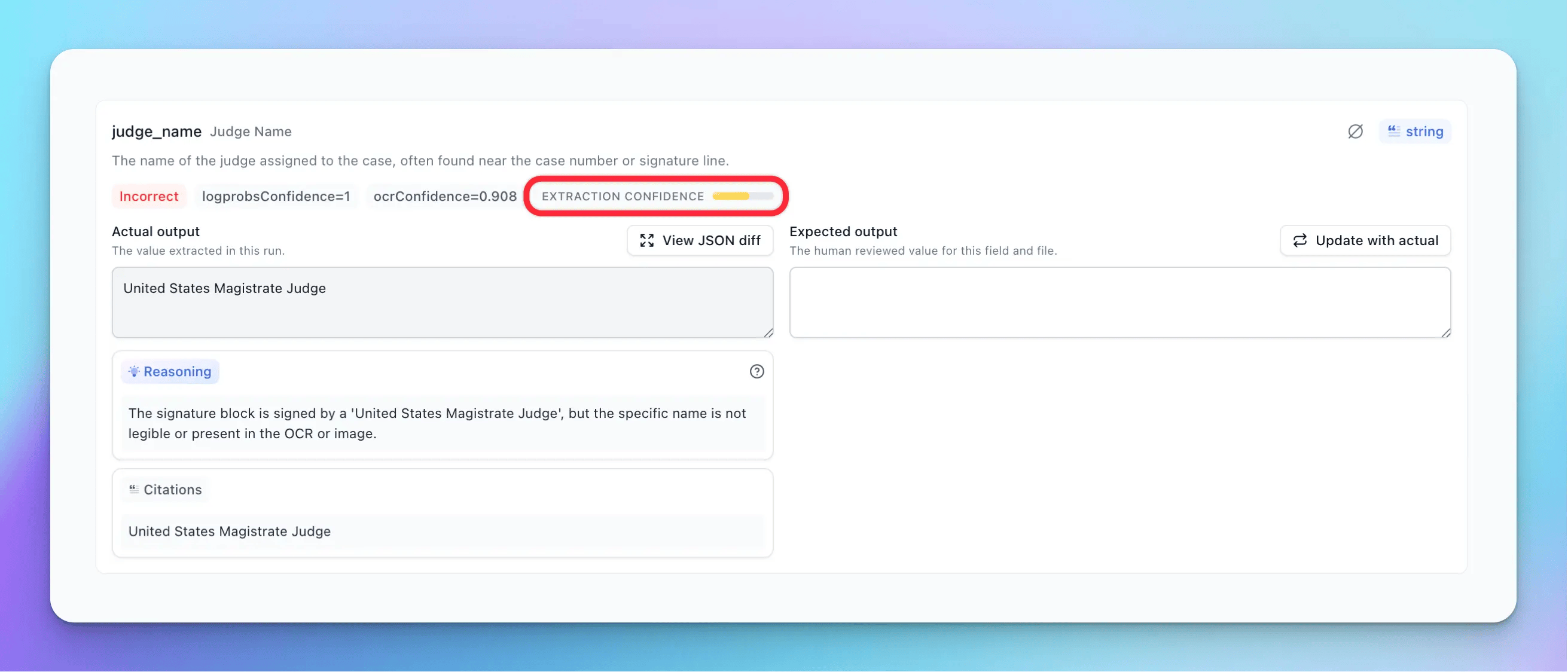
Precision vs Recall: Balancing Confidence Score Trade-offs
Precision measures how many extracted values are correct, while recall measures how many correct values the system extracts. Confidence thresholds control the trade-off between these two metrics.
Raising confidence thresholds improves precision by filtering out uncertain predictions. If a system only accepts extractions above 95% confidence, most outputs will be accurate. But recall drops because the system rejects more documents, including some that would have been correct.
Lowering thresholds increases recall by accepting more predictions. Coverage goes up, but precision falls as more errors slip through.
The right balance depends on which errors cost more. Accounts payable teams processing vendor payments lean toward precision since paying the wrong amount creates disputes. Loan processing workflows might favor recall to avoid rejecting valid applications, accepting that some fields will need correction later.
Continuous Improvement Through Confidence Score Feedback Loops
Feedback loops track how confidence scores perform against actual validation outcomes. When reviewers correct low-confidence predictions, the system logs whether the original extraction was right or wrong at each score level. This data reveals whether 85% confidence truly maps to 85% accuracy in production.
Patterns show up in correction data. If extractions scoring 88% confidence prove correct 95% of the time, the model is underconfident at that range. Teams can lower thresholds safely to reduce unnecessary review volume. If 92% confidence predictions fail 15% of the time, scores are overconfident and thresholds need to rise.
Some systems auto-adjust thresholds based on rolling accuracy windows. As models process more documents and validation data accumulates, confidence calibration improves without manual tuning. This adaptive approach keeps review queues sized appropriately as AI performance changes over time.
Document Processing Confidence Scores with Extend
Extend's confidence scoring system pairs calibrated model outputs with a multi-pass review agent that validates extractions before production. This agent analyzes each field, cross-references values against document context, and flags potential errors based on patterns learned from thousands of validation cycles.
The evaluation framework tracks confidence performance at field and document levels. As teams validate outputs through human-in-the-loop review, Extend logs actual accuracy rates at each confidence band. This data feeds back into threshold recommendations, surfacing when scores are over or underconfident relative to real-world performance.
Score calibration persists across document variations without manual retuning. The system handles layout differences, quality variations, and format changes while keeping confidence scores predictive. Teams using Extend report 99%+ accuracy rates while routing only 10-15% of documents to review queues.
Final Thoughts on Implementing Confidence Scores in Your Document Workflows
You need document processing with confidence scores that actually predict real-world accuracy, instead of output numbers that look authoritative. Proper calibration means your 95% threshold truly corresponds to 95% accuracy in production, so you can auto-process without second-guessing every extraction.
Teams shipping document automation can book a call to see how calibrated scoring handles their specific formats and volumes. Your thresholds become more precise as validation feedback accumulates, improving both accuracy and straight-through processing rates.
FAQ
How should teams set initial confidence thresholds for document automation?
Start by mapping your error tolerance to confidence levels: if the business can accept 2% errors, find the threshold where 98% of documents process correctly. Most teams begin with three bands: above 90% for auto-processing, 70-90% for review queues, and below 70% for manual handling, then adjust based on validation data and review capacity.
What does it mean when a model's confidence scores are poorly calibrated?
Poor calibration means the model's confidence scores don't match real-world accuracy. For example, predictions marked as 95% confident might only be correct 70% of the time. This breaks automation workflows because teams can't trust the scores to route documents reliably, leading to either too many unnecessary reviews or undetected errors reaching production systems.
Can confidence thresholds be different for specific fields within the same document?
Yes, field-level thresholds let teams apply stricter requirements to high-risk data while accepting lower confidence for less critical fields. Payment amounts might require 95% confidence because errors create vendor disputes, while reference numbers could process at 75% since they carry lower downstream risk.
When should confidence scores trigger a switch from precision to recall optimization?
Switch to recall optimization when missing valid documents costs more than correcting occasional errors. For instance, loan application workflows where rejecting legitimate applications hurts conversion more than fixing a few incorrect field values later. Precision optimization makes sense when errors create costly downstream problems like incorrect payments or compliance violations.
How do feedback loops improve confidence score accuracy over time?
Feedback loops track validation outcomes against original confidence scores to identify calibration drift. When human reviewers correct predictions, the system logs whether scores at each level matched actual accuracy, revealing patterns like 88% confidence predictions proving correct 95% of the time, which signals the model is underconfident and thresholds can safely drop.
