
Rapid Path to High Accuracy
When building document automation into your product or workflow, high accuracy is non-negotiable. But achieving high accuracy, especially across messy, unstructured documents, isn’t just a matter of using the latest model. It requires mapping unique business logic to your data schema, testing it against real-world edge cases, and building tight iteration loops to continuously improve over time.
In speaking with hundreds of AI teams, the biggest bottleneck to production-grade document automation isn’t the model — it’s the context. Models can only be as good as the inputs they receive: the schema, the field definitions, the examples, and the edge cases they’re tuned for. That’s how you turn a general-purpose model into a precision tool for your exact use case.
The teams shipping best-in-class accuracy are the ones that obsess over giving their models the right context. And the best way to achieve that is from technical teams working hand-in-hand with domain experts.
That’s why Extend makes configuration a first-class experience in the UI, not just the API. By putting domain experts in the loop, teams can achieve higher performance together. And engineers are freed up to build differentiated product experiences, by focusing on what happens downstream of getting accurate, reliable data from documents.
The Processor Configuration Experience
Extend supports three types of processors:
- Extractors: Your go-to when you need to pull specific data fields and line items from documents, regardless of their type or format
- Classifiers: Perfect for dealing with various document types sorting them into your custom categories
- Splitters: Ideal for messy, merged documents that you need to break into clean, separate subdocuments
Each processor is configurable. You can:
- Define the fields you want to extract (with types like currency, arrays, signatures)
- Add domain specific definitions and descriptions to improve model reasoning
- Prioritize for lower latency or higher precision
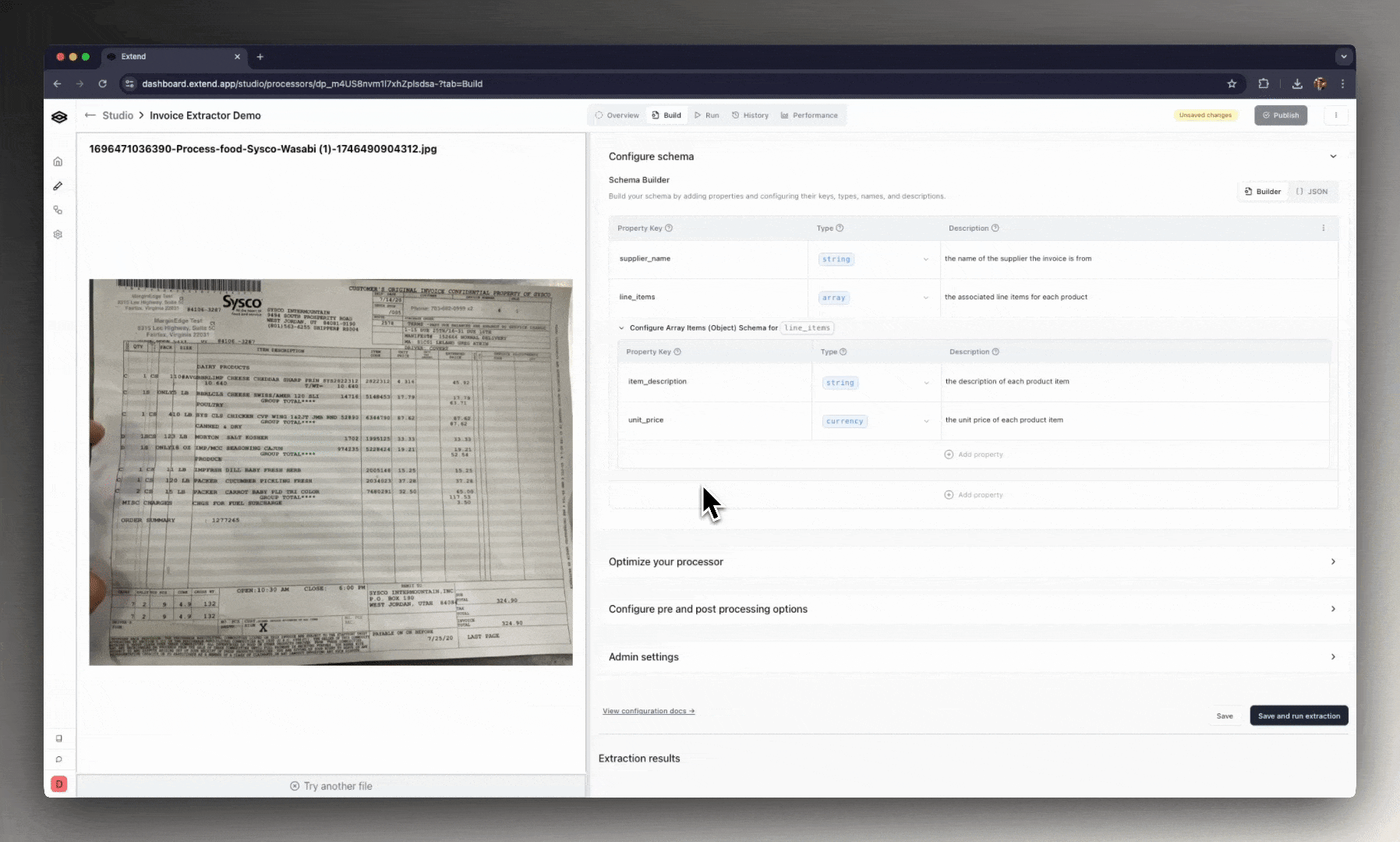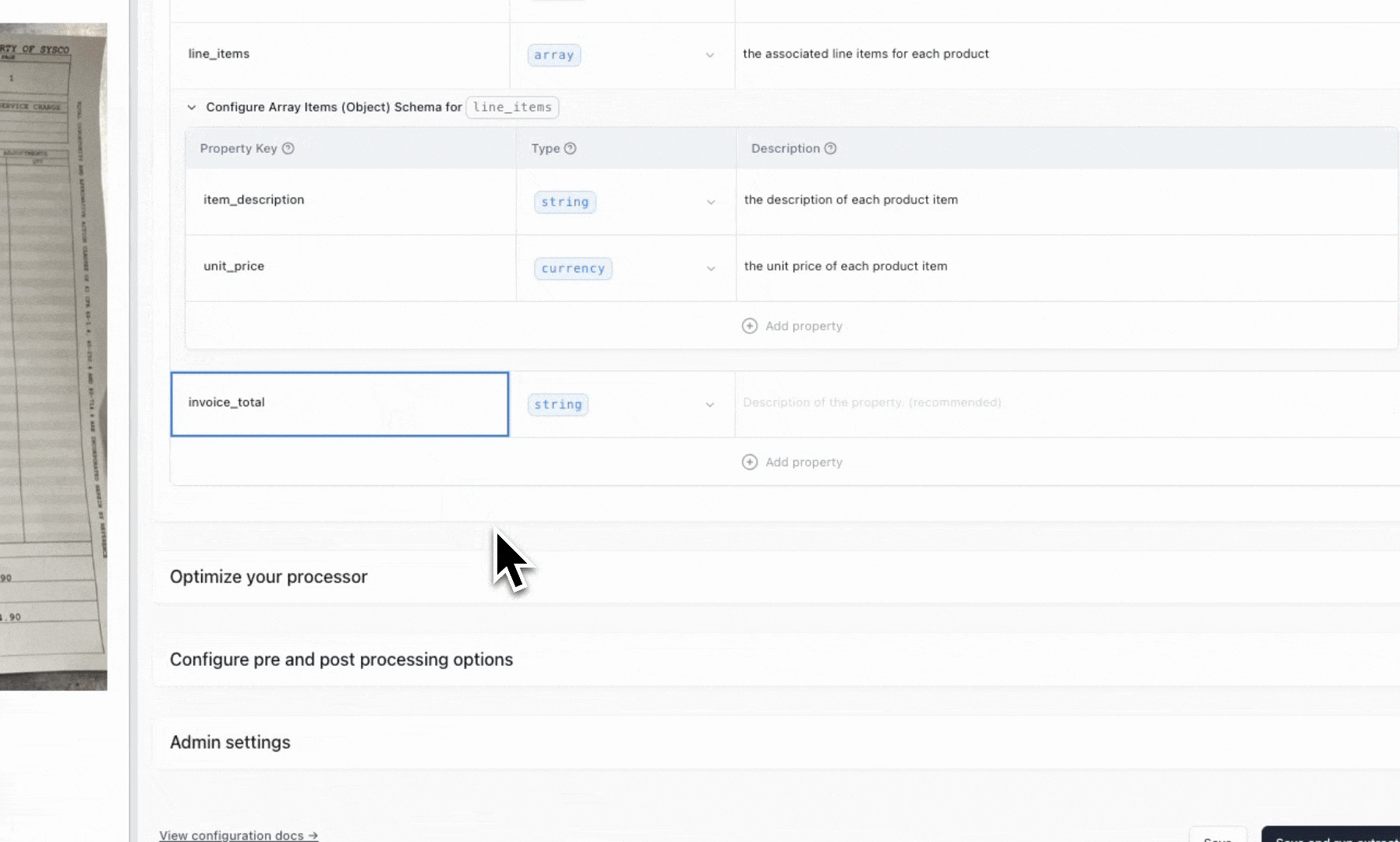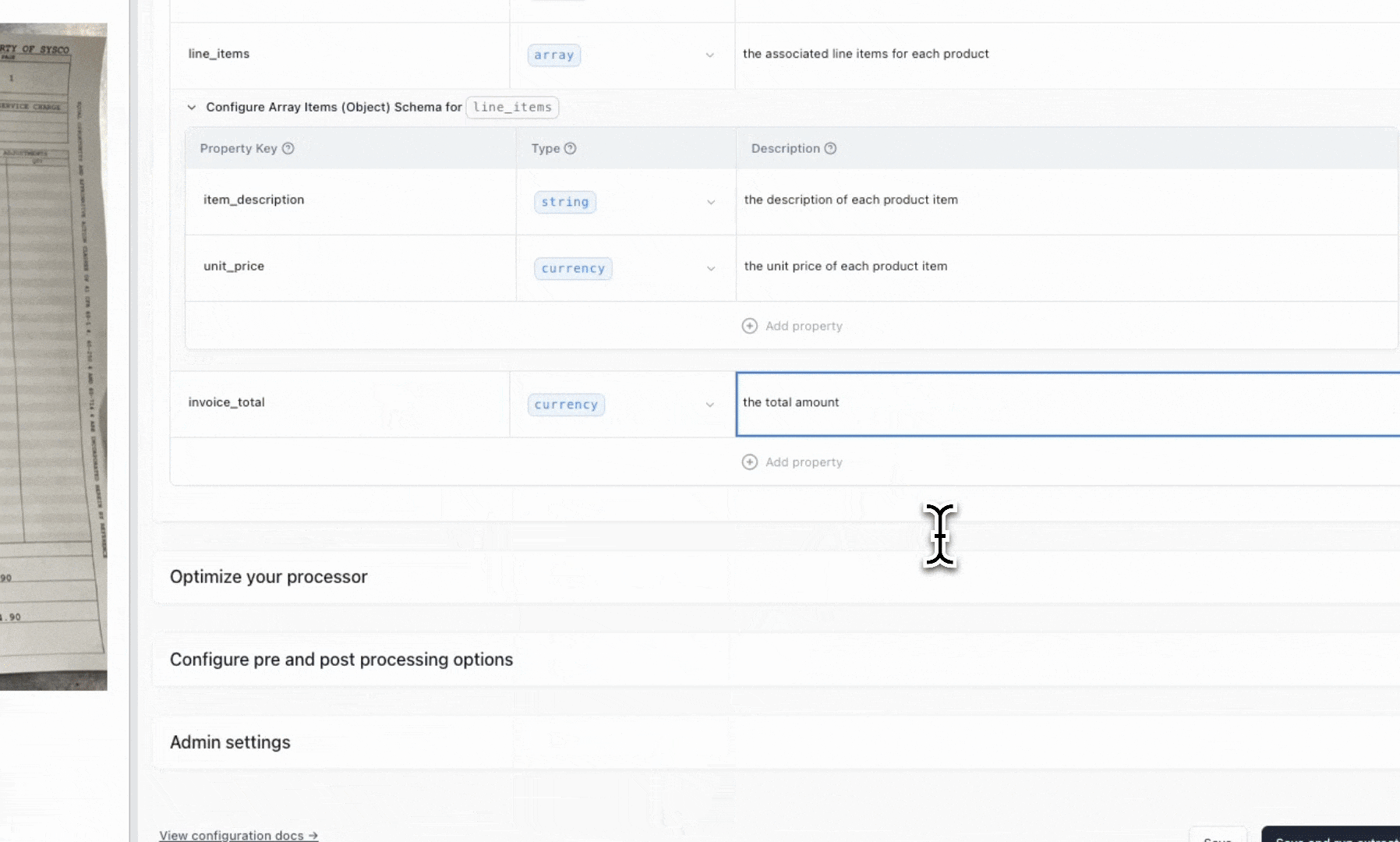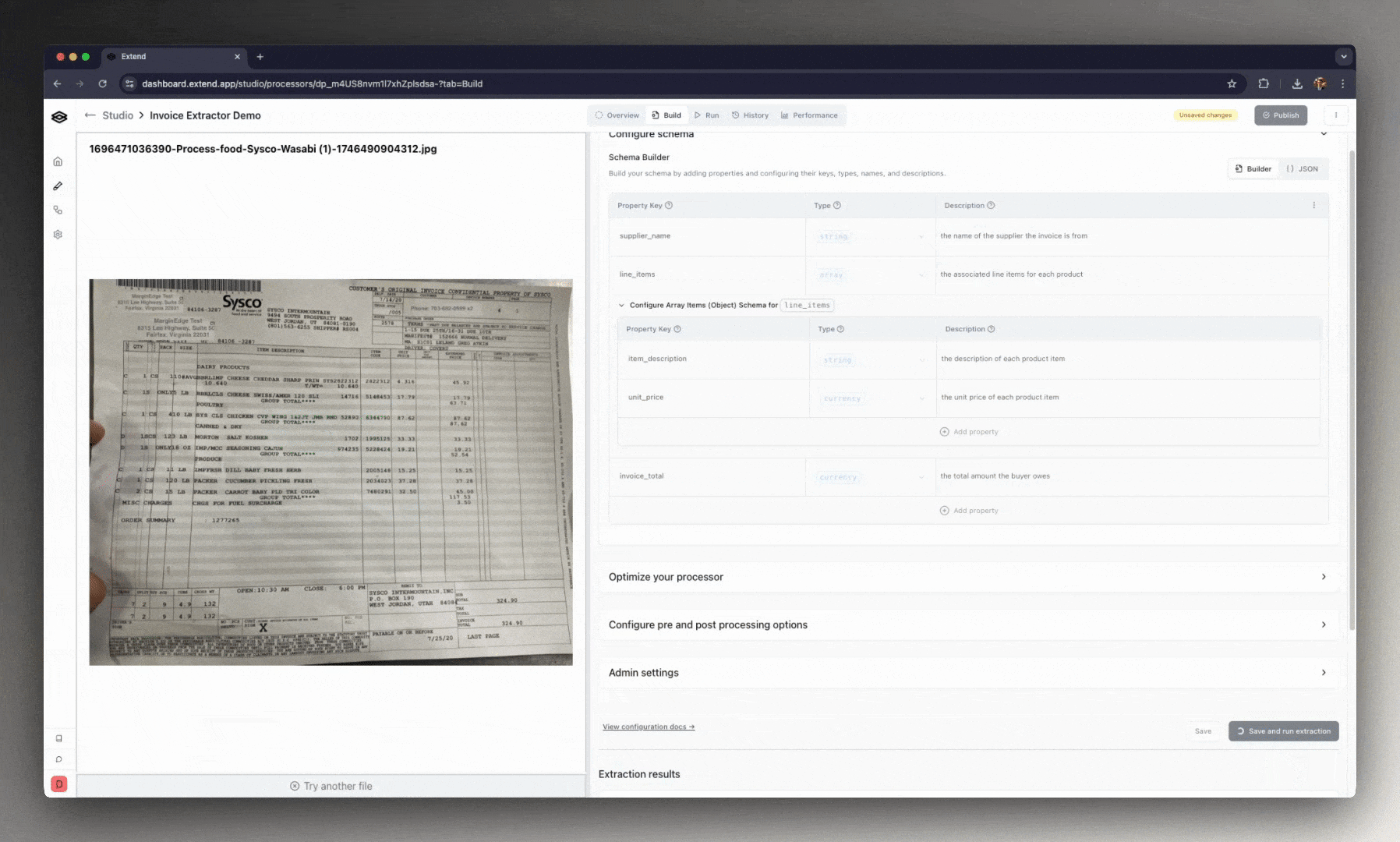
Every processor in Extend is built through a configuration UI. That interface includes:
- Field definitions: Add fields with types, descriptions, and schema (JSON Schema is the default format).
- Chunking & model options: Tune how documents are segmented and which base model powers the processor.
- Advanced options: Enable citations, reasoning insights, or multimodal support for visuals and handwriting.
- Versioning: Test changes safely in drafts, then publish versions and pin workflows to specific versions.
Configurations can be created via the UI or programmatically via API. Both are first-class. You can dynamically generate processors, update field definitions, and manage schema changes through your codebase if needed.
But once your processor is configured, the obvious question is: how do you know it will work in production?
Measuring Accuracy: Evaluation Sets
Public benchmarks aren’t enough. They don’t reflect the documents you care about: your formats, your vendors, your edge cases.
That’s why we built native support for a unified Configuration & Evaluation experience directly within Extend. Evaluation Sets are curated sets of files and expected outputs that serve as your testbed for accuracy, enabling you to:
- Upload your own labeled data, or…
- Use Extend’s AI-assisted labeling to bootstrap from scratch (the model takes a first pass; you just approve or correct)
- Create expected vs. actual comparisons across extractors, classifiers, and splitters
- Track precision, recall, and confidence field-by-field or class-by-class
- Iterate on your config and re-run evaluations to see the impact
The result is a fast feedback loop that lets you tune prompts, update schemas, or test new models—and immediately see what’s improved or regressed.
Extractor Evaluation Experience
Classifier Evaluation Experience
Splitter Evaluation Experience
Driving Value Across Teams
For Developers and Infra Teams
- Optimize tradeoffs between cost, latency, and accuracy by testing model versions and processor settings in real-world conditions
- Version processors cleanly for different pipelines or tenants
- Use the API to programmatically create, test, and deploy processor configs
For Operators and Domain Experts
- Own and iterate on processor behavior directly in the UI
- Review and correct outputs via human-in-the-loop flows
- Add examples and corrections that feed directly into future eval sets
This shared ownership model is what makes teams faster. Engineers don’t need to chase down edge cases. Operators don’t need to wait on code changes. Everyone works in one place.
Looking Ahead
Coming soon:
- Auto-optimization loops: Models that auto-tune configs based on your eval sets overnight
- Performance emails: Instant reports when a new model drops, showing impact on your data
- RL & memory systems: Use your eval data to fine-tune downstream steps automatically
If You're Building Document Automation and want faster iteration, better accuracy, and infra your team won’t have to maintain, talk to us here.
We’d love to show you what we’re building.
