
What Are Citations & Reasoning in Extend?
Any experienced developer knows that accuracy is only half the battle — the other half is trust. You extracted a field from a document, great. But how do you know it’s correct? And more importantly, how do you prove it?
At a high level, citations & reasoning in Extend are tools for grounding model outputs back to their sources. For every extracted value, field level bounding boxes will show where in the document that value was found. In more complex cases, reasoning metadata explains why the model arrived at that output.
Specifically, Citations will trace every extracted field back to the original coordinates, text, and visual region on the page. Reasoning will provide the logic the model used to derive each answer — not just the output, but the steps it took to get there, especially for inference tasks without a 1:1 text match.
Citations + Reasoning in Action
Inferring a Due Date
Take the classic case of invoice due dates. Not every invoice states it explicitly. For example, this invoice includes the “invoice date” and “terms,” both of which combined would equate to the due date.
With citations and reasoning enabled, as well as custom extraction rules, the model links the due date value to both the “January 1” and “Net 30” fields, and explain the inferred calculation in the metadata. That makes the extraction explainable and auditable.
Was this document signed?
When dealing with more complex true or false results, there are rarely pure text based matches in the document. With reasoning, the model can synthesize evidence across an entire document and arrive at a conclusion, showing its work for an operator to review.
In this example, despite there being no “signature” label, the model detects a handwritten element and understands it is a signature in the context.
Customizing your experience
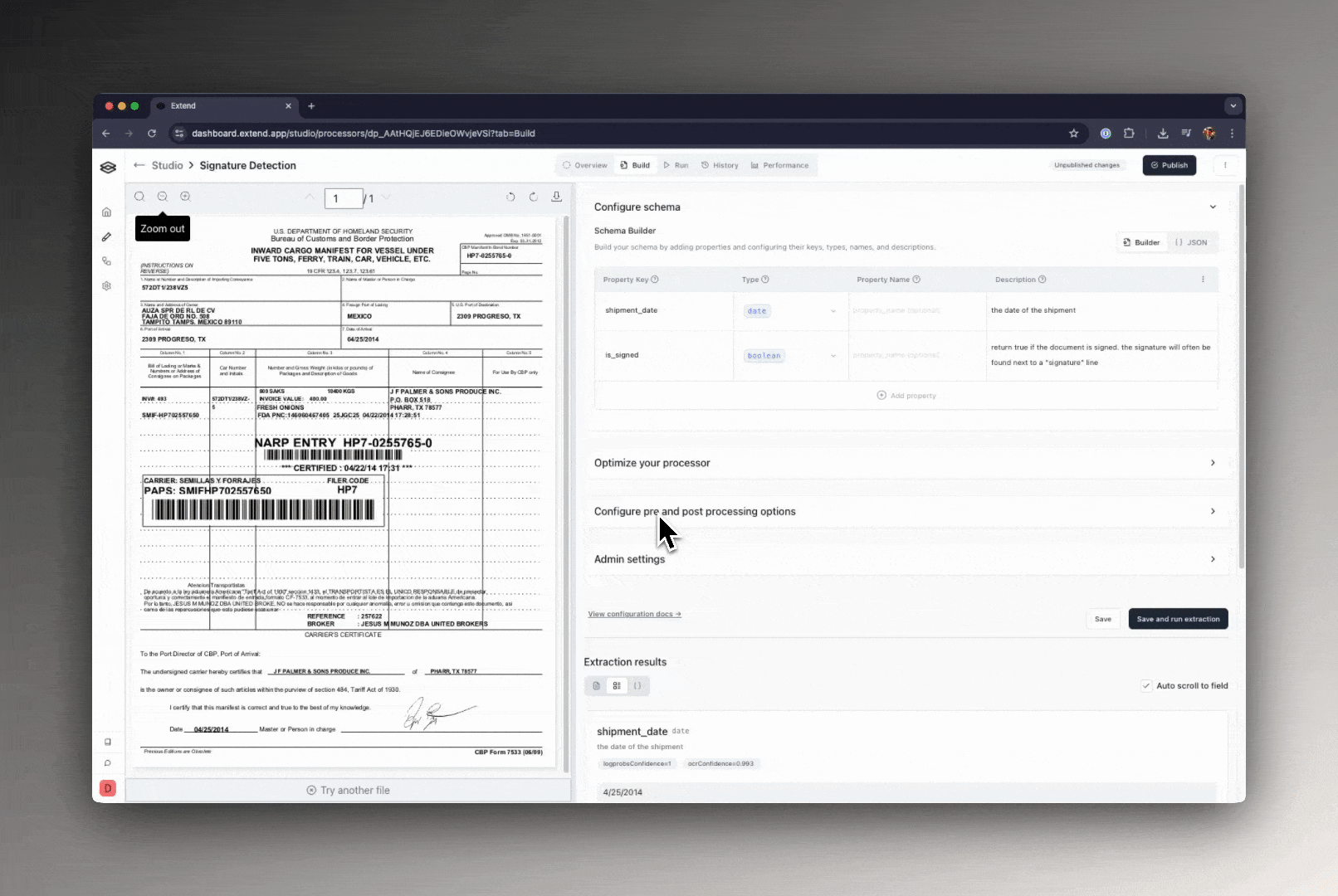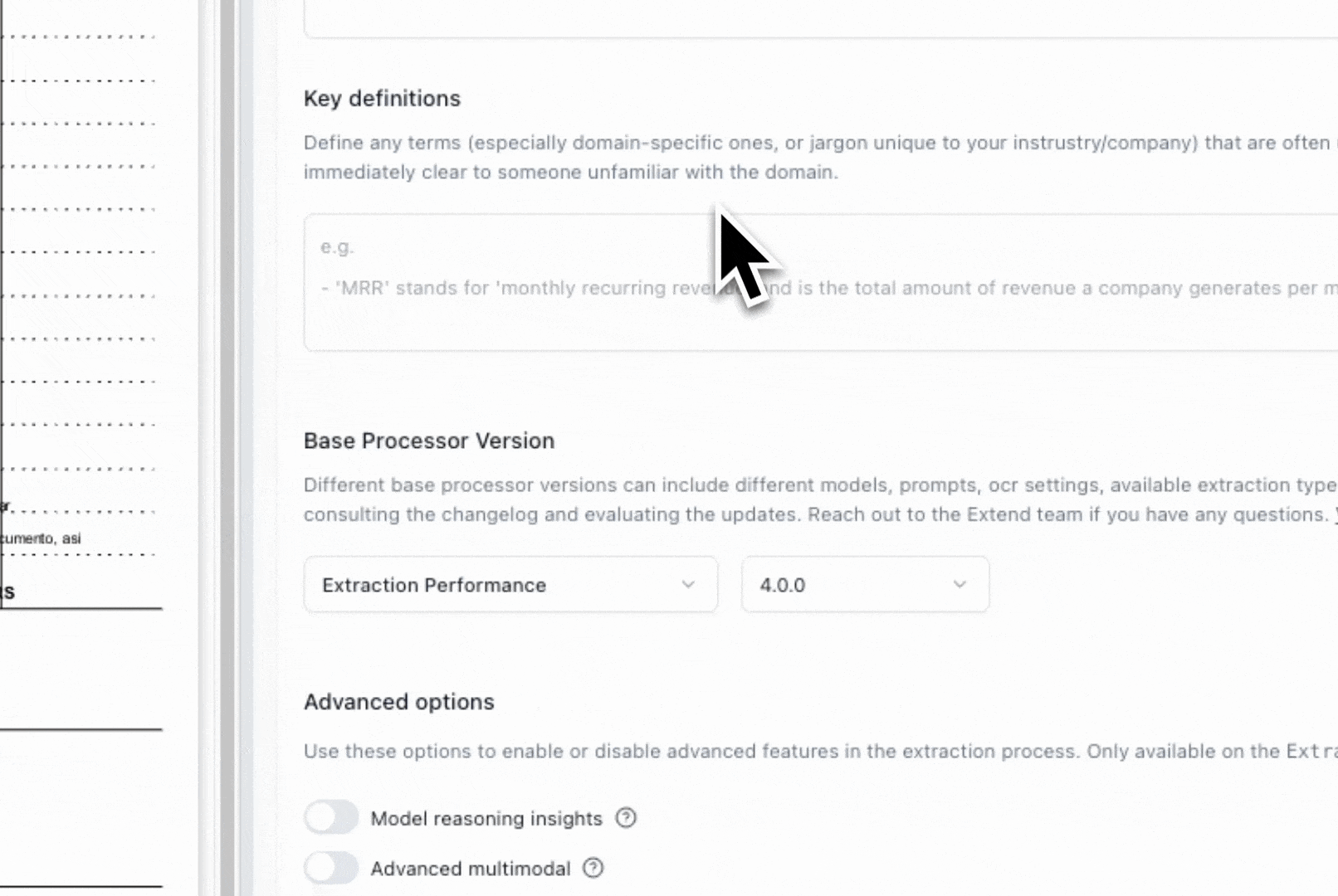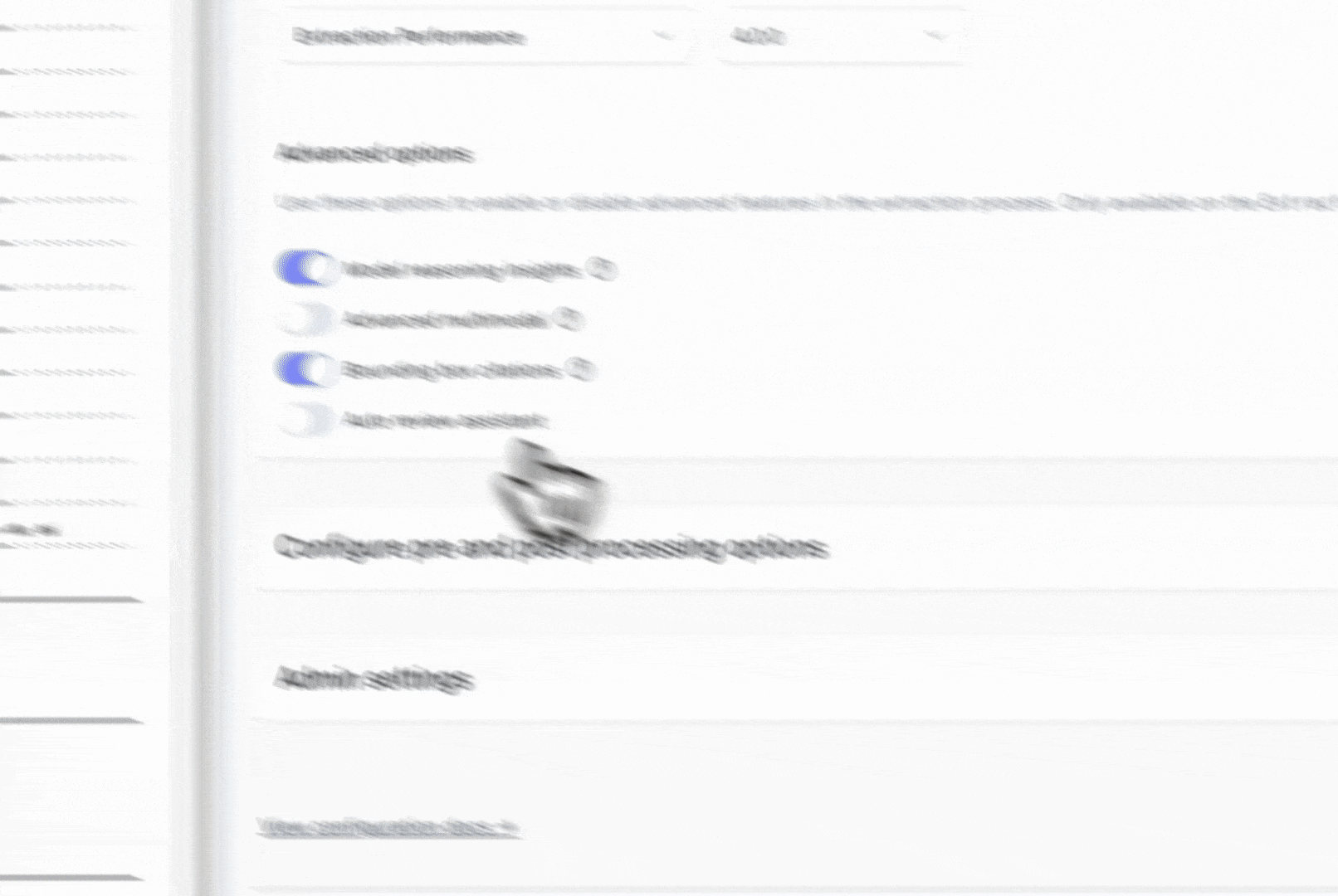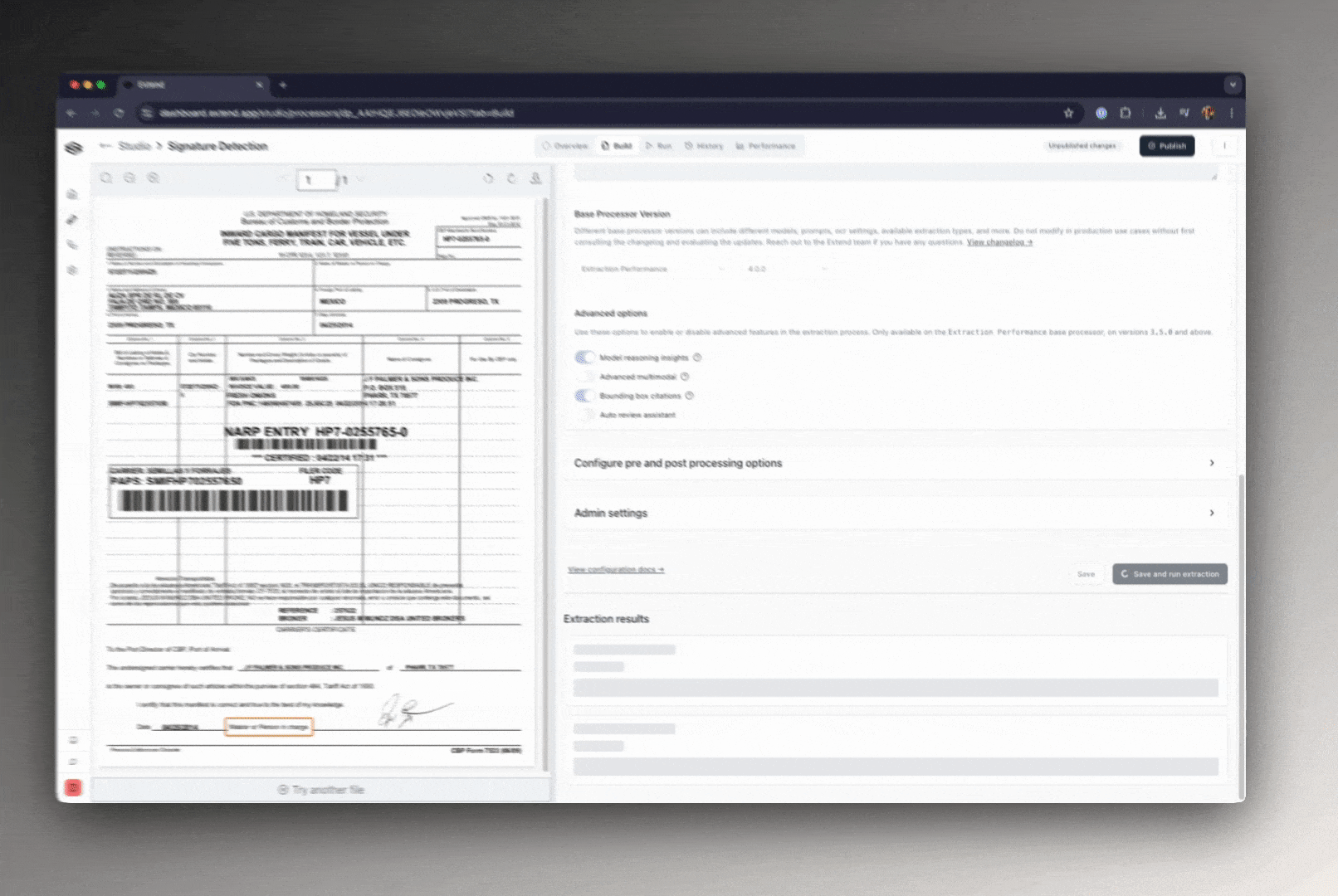
Extend offers two bounding box modes:
- Heuristic-based (default): For straightforward fields like invoice totals or vendor names, we apply rules and string matching to locate where in the document the value came from.
- Citation-based (optional): When bounding box citations are enabled, the model outputs internal reasoning traces. Extend captures those traces, resolves them to document coordinates, and returns bounding box coordinates via API.
This enables citations even for inferred values — not just copied strings.
Both options are returned in structured metadata alongside the extracted data, and can be consumed by your frontend, review tooling, or downstream systems. As a note, enabling bounding box citations and reasoning insights increases latency.
Creating Value Across Use Cases
For Developers and Platforms
Citations enable better product experiences. By attaching bounding box coordinates to each field, you can:
- Overlay extracted values directly on the source document in your UI via API
- Build user trust by showing exactly where data came from
- Decide when and where to prioritize latency vs. interpretability by toggling citations on/off per processor
Companies like Brex use field-level overlays in-product to show users exactly where extracted data came from on their receipts and invoices, which helps build trust and improve adoption.
For Operators and Reviewers
For internal review teams, citations accelerate the verification & approval process. Instead of hunting through a PDF to review an output, Extend will snap to the relevant page, highlight the specific coordinates, and explain why the model arrived at the extracted value.
If You're Building Document Automation
And you need to handle reasoning, reduce errors, or just help your team understand what the model is doing — talk to us.
