
At Extend, we build APIs for document processing: parsing, extraction, classification, and splitting. Building a high-accuracy processor is fundamentally an encoding problem, disguised as prompt engineering. You are trying to take human domain expertise (the intuition of a team that has handled thousands of documents) and encode it into field descriptions and classification rules that an LLM can reliably execute.
Consider this frustrating sequence of events:
User: The classifier gets 85% right, but it keeps confusing a "house bill of lading" with a "master bill of lading". Let me update the prompt to explicitly explain the difference.
LLM: Got it! House bills of lading are now classified perfectly.
User: Great. Wait, why is it suddenly failing to recognize invoices?
So you fix the invoices. Now it starts to misclassify packing lists. You add a rule, then an exception to that rule, then an exception to the exception. Days pass stuck in this cycle:

The problem is that humans aren't good at this sort of task. Testing prompts, iterating, and manually updating rules is tedious. We can't track how a change in one rule will ripple through a 50-class classifier, and we can't see the high-dimensional space the model is navigating.
But labeling examples is easy. Pointing at a document and saying "this is a house bill, that is a master bill" requires only domain expertise (not prompt engineering). Our core insight was this: If an agent can take those labels and figure out the rules automatically, the human never has to touch the prompt at all.
That is exactly what Composer does. Today, customers use it to regularly push classification accuracy to ~99% on eval sets that previously plateaued at ~85%.
But getting here meant throwing out our first architecture, developing opinions on problems most agent frameworks ignore, and discovering that the most valuable thing Composer does is something we never planned for. Our domain is document processing, but the patterns are general: workflows vs. agents, context window management, and idempotent triggers for long-running tools.
If you're building agents, we hope our mistakes save you some time.
First Attempt: The Workflow Approach
Our first proof-of-concept was a workflow. It was heuristic-based and deterministic, with AI involved only at the final step of generating new descriptions.
The logic went like this: an extraction schema has individual fields. Naively, you can assume each field is independent of the others and can be optimized separately. If the invoice_total field has 73% accuracy, we look at the errors for that field, generate a better description, and move on to the next field. One inference call per field. Simple decomposition.
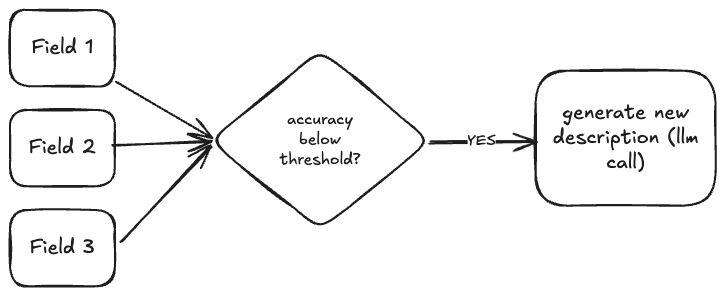
For simple schemas with a handful of flat fields, this worked. If you have five flat fields that genuinely don't interact with each other, optimizing them independently is fine.
Where It Broke Down
The independence assumption falls apart quickly as schemas get more complex.
Array fields create multi-level descriptions. A line_items array has descriptions at the array level and for each property within it. These levels interact during extraction, but our workflow optimized them separately. The heuristics for ordering and resolving conflicts between levels became increasingly convoluted.
Related fields interfere with each other. Fields like length, width, and height in an item_dimensions object should have similar descriptions since they extract measurements from the same part of a document. But optimizing them independently produces conflicting descriptions that could fight each other.
Classification killed the workflow entirely. Classification is where our approach collapsed. Classification classes are mutually exclusive—to optimize one class, you need to know what else is in the schema so you don't create overlap. A lot of classification rules are about disambiguation: "This is a house bill of lading, NOT a master bill of lading, because of X."
When we tried to build heuristics for all the possible relationships between classification classes, we hit combinatorial explosion. You can't enumerate every pairwise interaction in a 50-class classifier and write deterministic rules for each one. The code paths multiplied faster than we could handle them.
The Pivot to Agents
We pivoted after we hit a breakthrough realization: this is a high-dimensional optimization problem, and navigating high-dimensional spaces is exactly what agents are good at.
Instead of trying to decompose the problem and write code for every case, we could reframe it. Give the agent the full picture—the schema, the errors, the relationships between fields—and let it figure out what to optimize and how, with the right tools for the job.

This also meant that as models get smarter, Composer gets smarter for free. With the old approach, every model upgrade meant rewriting heuristics by hand.
Switching to an agent didn't magically fix everything. It changed the problem from "how do I write heuristics" to "how do I present information to the agent so it can actually do its job." Here's what we learned figuring that out.
Our takeaways
1/ Context Engineering Is The Real Work
We built the classification optimizer first because workflows failed fastest there—the mutual exclusivity problem made heuristics infeasible—and because classification has simpler context requirements. The output is a single label, and evaluation is binary: either the predicted class matches the ground truth or it doesn't.
We threw together a minimal agent with basic tools and almost no prompt engineering. It worked immediately. We ran it against our hardest internal evaluation sets—classifiers with subtle distinctions between visually similar document types—and watched accuracy climb to ~99%. But classification simplicity hid a landmine we stepped on later: context window limits. We encountered it in 2 ways:
First, the error analysis itself. A classifier's confusion matrix is an N×N structure. For a classifier with 200 classes, that's 40,000 cells. Even with aggressive compression, presenting the full confusion matrix to the agent would consume the entire context window before we'd included any actual document content or error analysis.
We solved this with aggressive filtering: only show classes that were actually confused with each other. If Class A was never misclassified as Class B, there's no reason to present that cell to the agent. This reduced the context from O(N²) to O(errors), which was manageable.
Second, which documents the agent sees. We found that we got better results by showing the agent only the misclassified examples and telling it "everything else was correct." This focused its attention on the actual problems rather than having it reconsider things that were already working.
The lesson: context is precious. Every token you spend on background information is a token you can't spend on the actual problem.
2/ Small Tool Design Choices Add Up
Batch over parallel
Early on, we tried to leverage parallel tool calling: the model would emit multiple tool calls, and we'd execute them concurrently. This was unreliable. The parallel calls would sometimes be inconsistent with each other, or the model would make calls that only made sense if executed in a specific order.
We switched to batch-style tools. Instead of the model making five separate update_field calls, it makes one update_fields call with a list of updates. The tool handles the batching internally.
# Instead of this:
update_field("name", "desc1")
update_field("address", "desc2")
update_field("total", "desc3")
# We do this:
update_fields([
{"field": "name", "description": "desc1"},
{"field": "address", "description": "desc2"},
{"field": "total", "description": "desc3"},
])
Collapse List & Get
A common agent pattern is: list available items, then get details on specific ones. For example: list_fields() returns field names, then get_field_details(field_id) returns the full schema for that field.
We found it more effective to collapse these. Return paginated results with full objects, not just IDs. The model makes fewer round trips, and you avoid the failure mode where the model lists items and then forgets to fetch the details it actually needs.
# Instead of this:
def list_fields() -> list[str]:
"""Returns field IDs only."""
def get_field_details(field_id: str) -> FieldSchema:
"""Returns full schema for one field."""
# Do this:
def get_fields(page: int, page_size: int) -> list[FieldSchema]:
"""Returns paginated fields with full schema included."""
Schema References with JSON Pointer
We needed a way for the agent to refer to specific locations in nested schemas. If it wants to update the description for line_items.properties.unit_price, it needs a consistent syntax that the agent can generate and our tooling can parse.
We used JSON Pointer (RFC 6901). It's a standard the model has likely seen in training data, so it generates valid pointers without much prompting. We can parse them reliably and apply updates to the right schema locations. Using standards from RFCs means less custom syntax to teach the model and fewer edge cases in our parsing code.
3/ Long-Running, Expensive Operations Require State
Most agent frameworks assume tool calls are fast and cheap. Ours are not.
When Composer runs an evaluation set against a processor, it's potentially processing hundreds of documents through extractors and classifiers. This can take a long time: 30 minutes and sometimes an hour for large sets. It also costs money in inference and processing fees.
So we built a simple persistence layer that separates "triggering" an operation from "waiting for"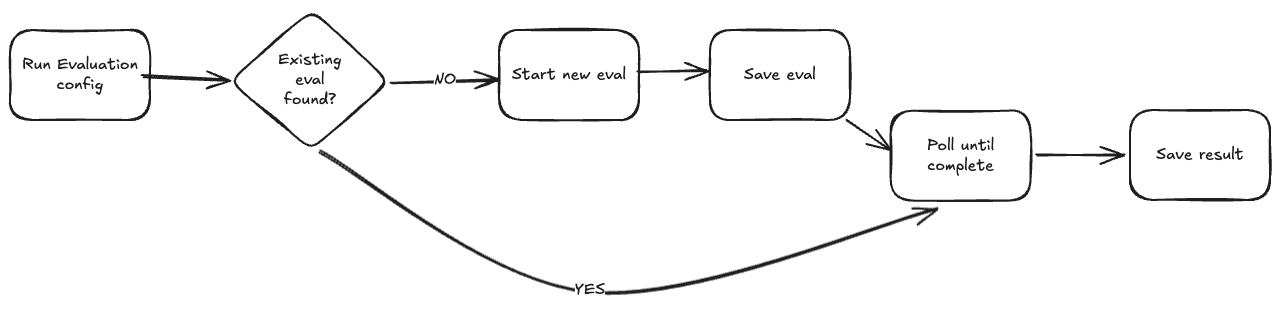
The key behaviors:
- Idempotent triggers: When the agent requests an evaluation, we first check if we've already kicked one off for this configuration. If yes, we return the existing operation ID and wait for it.
- Persistent state: We write the operation ID to storage immediately after triggering. If the agent crashes and restarts, we can look up in-progress operations and resume waiting.
- Polling over blocking: Tools return quickly with an operation ID, then poll for completion in a loop. This lets us update the agent's state with progress information and handle timeouts gracefully.
It's not elegant. It's a quasi-workflow engine bolted onto an agent framework. But if your domain involves expensive, long-running operations, you'll need something like it.
The lesson: Most agent frameworks assume tool calls return in seconds. If your domain involves expensive, long running operations, Idempotent triggers and persistent state tracking aren't optional.
4/ Your Agent Might Solve a Different Problem Than You Intended
The most interesting thing we learned wasn't planned. We built Composer to make "number go up"—to maximize accuracy. What we discovered was that, even when Composer was ill prepared to make the number go up, it was still able to explain to the user why the number can't go up.
When Composer runs and accuracy doesn't improve, it reports what it found. And these reports turned out to be remarkably useful. For example:
- "Documents A and B have identical content but different labels"
- "The date field is sometimes labeled with the invoice date and sometimes the due date"
- "This field you're asking me to extract doesn't exist in these documents"
Users run Composer hoping for better accuracy. Composer says "I can't do better because your labels have these problems." Users fix their labels, re-run, and the accuracy jumps. When Composer "fails" to improve accuracy, it's not actually failing. It's doing a different kind of useful work. We only recognized this because we externalized the agent's reasoning. If Composer had been a black box that just output configuration updates, we'd never have seen it.
The lesson: Externalize your agent's thinking. Log the reasoning traces. Surface intermediate conclusions to users. You might find the "side effects" are as valuable as the primary output.
What’d we do differently
Building Composer took longer than it should have. Some of that is inherent to R&D: you don't know what will work until you try it. But some of it was self-inflicted.
Focus on the problem before the system. We built distributed infrastructure before we'd validated the approach. When we pivoted to agents, all of that became baggage we had to refactor or throw away. We should have started with scrappy Jupyter notebooks and single-threaded scripts.
Invest in fast feedback loops early. A single experiment ("does this prompting approach work better?") took hours to run and days to analyze. If we'd built tooling for parallel comparison and automated metrics dashboards from the start, we'd have converged weeks faster. Experimentation velocity dominates everything else in R&D.
Decouple experimentation from production engineering. Good code in service of the wrong approach is worse than throwaway code that finds the right approach faster.
Wrapping up
If you're building your own agents, here's what we hope resonates:
- Let agents do what they're good at
- Starve your context
- Design for expensive operations
- Externalize reasoning
- Productionize last
Composer exists because we were trying to solve a tedious problem for our users. What we learned along the way applies far beyond document processing. Agents are a new paradigm, and we're all still figuring out the patterns.
We hope sharing ours helps you find yours faster.
Composer is live in Extend for classification and extraction optimization. Check out the docs or reach out if you want to see it in action.
