
Document splitting—taking a large PDF containing multiple documents and figuring out exactly where one ends and the next begins—is a deceptively difficult task.
It requires understanding page-level content, holding massive context in memory, and making nuanced judgment calls about boundaries across hundreds of pages. It is essentially document classification plus localization, done in bulk.
Even the best frontier LLMs struggle with this task out of the box. We built multiple internal benchmarks to pinpoint why, using those failures to drive the development of Extend’s splitter solution. Today, we are releasing the results from one of those benchmarks, and will be releasing the source data and an example schema in the coming weeks.
The Takeaway
Frontier models are reasonably good at avoiding incorrect splits, but they miss a lot of the boundaries they should find. The best raw model (Gemini 3.1 Pro) only catches about half of the expected subdocuments.
Extend's harness catches roughly two-thirds or more of boundaries for every underlying model and moves F1 toward 72%, adding 8.3 to 28.4 points over direct model use.
Interestingly, a higher raw baseline doesn't always mean better harness performance. Splitting performance depends more on the system than the model.
Results Analysis
Raw frontier models miss real boundaries. They have decent precision (they rarely split incorrectly), but terrible recall (they miss massive numbers of actual splits). This is typically because models combine groups of unrelated supplements or multiple contiguous forms into a single subdocument.
Extend closes this gap by wrapping the frontier model in a dedicated splitting pipeline. Our system controls parsing via proprietary models, manages context across smaller chunks, and reconciles boundaries across the entire document. The LLM is focused purely on understanding the document and its language.
The visualization below shows raw model F1 compared with the same model wrapped in Extend's harness.
The Limitations of Raw LLM PDF Splitting
- Chunking kills context. Most models can't fit a 100+ page document in one call. Chunking loses information right at the boundaries where splits happen.
- No control over document representation. When you upload a PDF to an API, the provider decides how to OCR and render it. You can't control what the model sees.
- Splitting needs global context. You need to know the full document structure to decide where boundaries fall. A single prompt under context pressure can't do this well.
- Some splits are conditional. Whether a page is its own document can depend on what came before it. You can't just process pages in parallel.
We built Extend's splitter to handle these problems.
Our Methodology
PoliTax Split is a hand-labeled benchmark from 74 compound tax documents released into the public domain by the last four White House administrations. The documents are long (often 100+ pages) with subtle boundaries, for example official government tax forms interleaved with various supplements. Here are a few pages from one of the documents:
We took a subset of this benchmark consisting of its 30 largest documents and evaluated baseline performance against the current frontier models from each major provider: Google's Gemini 3.1 Pro and 3 Flash, Anthropic's Claude Opus 4.6 and 4.5, and OpenAI's GPT-5.4. We compare this to the performance of Extend’s latest “light” splitter, v1.3.0.
Extend's harness handles how the document is represented, how context is preserved at chunk boundaries, and how split decisions are validated across the full document.
Extend’s splitting system uses a sequence of house-built parsing models, dynamic routing systems and a mutli-pass review system to eliminate edge cases that models struggle with when using their native PDF modes. This benchmark was created as a development tool to help discover those edge cases, so we limit the benchmark harness to only use features native to each provider’s API.
To create a robust benchmark, we developed a “best effort” strategy for evaluating frontier models against each other and against the Extend Splitter using each model. It represents the baseline infrastructure any engineering team would need to build just to get a model running on large documents without using a product like Extend:
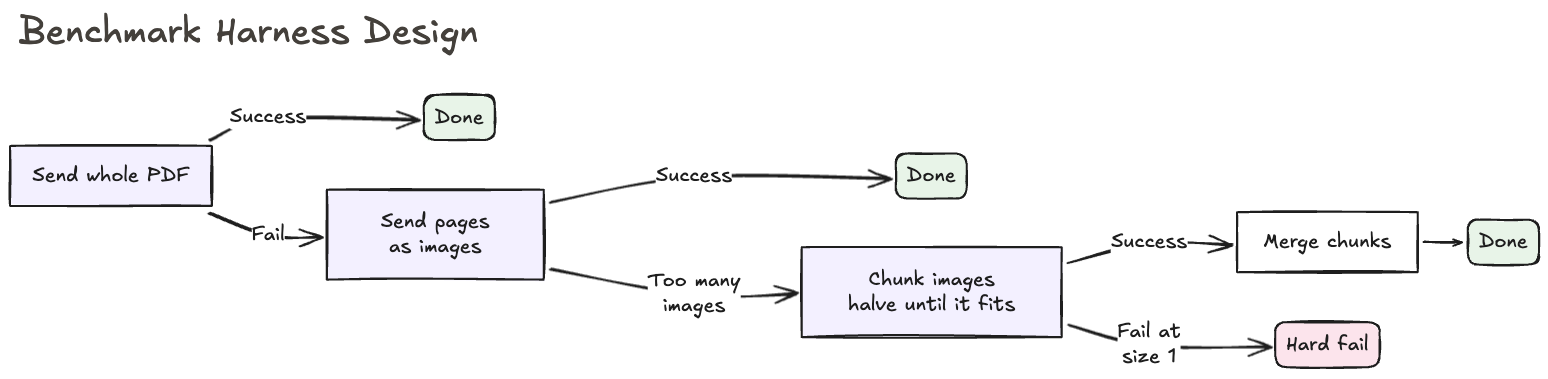
1. Native PDF upload to the model. Some model providers also automatically OCR the document under the hood in this mode.
2. Page images. If the provider rejects the direct pdf upload due to file size or page limits, we render every page as an image in one batch.
3. Chunked images. If the unchunked prompt covers more than 75% of the context window, or we reach a image count input limit, we progressively reduce chunk size by 5 pages until a call succeeds, then merge chunk results with matching type boundaries.
Without fallbacks 2 and 3, most providers would fail immediately on a significant portion of the documents in this benchmark. To mitigate that, we felt this “best effort” strategy would create a better representation of actual raw model performance.
Crucially, raw performance is affected by how the model ingests the document. As the chart below shows, models with robust native PDF support (Gemini) utilized that method most often and scored highest out of the box. Models that required more chunked images (Claude, GPT) saw their raw F1 scores drop significantly, falling to the 37-46% range.
Where Raw Models Break Down
We categorized common errors across all raw models. In every case, the model stops following instructions when the visual layout suggests a different answer.
- Supplements absorbed into parent forms: Models lump machine-generated supplementary pages in with the form above, ignoring instructions to split them out.
- Duplicate forms merged: When the same form type appears back-to-back, models combine them into one sub-document instead of splitting each instance.
- Classification errors cascade: If a model misclassifies one unfamiliar form, it often repeats the same mistake for the rest of the document.
- Grouped supplements over-split: Supplement pages with sequential statement numbers should stay together, but models often split on every visual break.
Production Performance
To put these numbers in context: a customer recently sent a 1,044-page loan document through the splitter. It found 315 sub-documents in 4 minutes and 43 seconds, including parsing (0.27 seconds per page).
No frontier model can handle a document of that scale in a single pass reliably. Even with large theoretical context windows, you face minutes of processing time for the API call alone, with no guarantee the model holds context across the full document.
